改进UNet++遥感影像建筑物变化检测
作者: 孙雯婷 施文灶 王磊 温鹏宇 庄镇榕 杨玮琦 李甜
摘要:传统遥感影像建筑物变化检测的方法,其算法简单,对中低分辨率、信息量少且简单的影像有较好的检测效果。但随着影像分辨率的提高,遥感影像所含的信息量大且复杂,而且检测类不平衡,这使得传统的方法误差变大,其检测结果的误检和漏检都很高。为了能够适应更高分辨率的遥感影像,解决上述问题,该文提出一种深度学习的方法,具体为以UNet++为骨干网络,改进此网络的编码器为孪生卷积网络,以残差网络代替全卷积网络模块,并且引入注意力机制,最后用多边融合输出得到变化检测结果。通过上述改进的验证,与其他变化检测的方法相比,在精确率、召回率、F1分数和总体精度四个评价指标上均有不同程度的提高,分别达到了0.896、0.873、0.875和0.967。
关键词:建筑物变化检测;编码器-解码器;UNet++;注意力机制
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)25-0020-06
开放科学(资源服务) 标识码(OSID) :
1 引言
变化检测通过在不同时间观察对象或现象来识别其状态差异的过程[1]。遥感影像建筑物变化检测是一种通过多次观测来检测和提取建筑物语义变化信息的技术。导致遥感影像建筑物的语义变化的因素有很多,如建筑物的增加、建筑物的消失和建筑物的几何形状发生变化。遥感影像建筑物的变化检测具有多种应用,如城市变化监测、非法建筑识别和灾害管理等。随着卫星成像技术的发展,许多高分辨率的遥感影像可以更容易地获得。在高分辨率遥感影像中,地物具有更多的空间和形状特征,因此,高分辨率遥感影像成为变化检测的重要数据源[2]。有效提取和学习高分遥感影像中丰富的特征信息,减少伪变化的干扰,即没有真正发生的变化和不感兴趣的变化,进一步提高变化检测的准确性是遥感变化检测领域的重要课题。
在过去的几十年,学者们开发了大量的遥感影像建筑物变化检测方法。传统的变化检测方法可以分为两类:基于像素的变化检测和基于对象的变化检测[3]。基于像素变化检测方法,其主要利用像素的文本特征,如差值法、多波段指数法、机器学习法[4-6]等。基于对象的变化检测方法更适用于超高分辨率图像中的变化检测,利用对象作为过程单元来提高最终结果的完整性和准确性。由于可以在图像对象中提取丰富的光谱、纹理、结构和几何信息,因此在基于对象变化检测[7]中主要研究使用这些特征的双时间对象的相似性分析。
最近,深度学习的方法在计算机视觉领域优于传统方法。因为类人推理和体现输入图像语义的鲁棒特征的好处,它们取得巨大成功,因此基于深度学习的遥感影像变化检测也成了研究的热门[8-11]。在文献中,已经进行了大量尝试来使用深度学习技术解决变化检测问题。深度学习的方法可以分为两类,基于度量的方法和基于分类的方法。而目前的这些方法对遥感影像建筑物变化检测的准确率较低。为了提高检测的准确率,该文针对遥感图像建筑物数据集的特点,即大部分的遥感影像建筑物变化的数量远小于不变的数量,提出解决办法。该文利用UNet++作为主干网络,引入孪生卷积网络作为编码进行特征提取,利用残差网络代替全卷积网络,来获得更多的判别特征表示,使得变化特征更具备鲁棒性。除此之外,双时相的遥感图像因为拍摄的时间不同,可能会出现配准误差,这会引起边缘检测错误导致变化检测也会出现误差,本文为了解决这个问题,使用自注意力机制,其能够捕获更丰富的时空关系,获得光照不变和配准误差的鲁棒性特征。
2 改进UNet++网络架构
遥感影像建筑物属于小目标物体,使得建筑物的变化在遥感影像上显得很小。解决建筑物小目标对象问题的最佳网络架构是编码器-解码器风格的架构,并且编码器-解码器架构具有高度的灵活性和优越性,它可以同时考虑抽象能力和位置信息。
为了减少来自编码器和解码器子网络的特征图之间的语义差距,周等人提出了UNet++[12-13]的新型医学图像分割结构。UNet++使用了一系列嵌套和密集的跳跃连接,融合了来自编码器和解码器不同比例的特征图,不同比例的特征图有其独特的信息,在遥感建筑物变化检测过程中产生的特征图,低级详细特征图捕获丰富的空间信息,突出建筑物的边界,而高级语义特征图则包含位置信息,用于定位建筑物所在的位置。因此UNet++能够保持图像的特征和细粒度的定位信息,从而产生较好的分割结果。
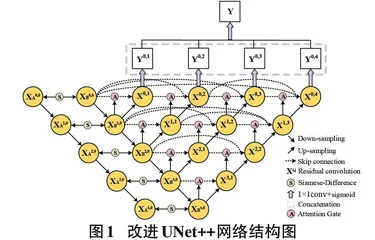
变化检测可以视为二值图像分割的问题,所以引入高级语义分割架构来解决变化检测任务。受到UNet++的启发,以UNet++作为骨干网络对遥感图像建筑物的小目标进行语义分割以及进一步的变化检测,都具有很好的潜力。以此为基础,开发了一种基于高分辨遥感影像的端到端变化检测结构,详细结构图如图1所示。首先两个时期的图像通过孪生卷积网络作为变化检测网络的输入,孪生卷积网络的两个分支对图像分别进行处理,两个分支网络具有相同的结构,并共享参数。两个分支下采样融合了两个分支的特征,融合后的高分辨率、细粒度的特征通过跳跃连接依次传输到解码块,补偿解码器深层位置信息的丢失。采用具有密集跳过连接的UNet++模型作为主干网络来学习多尺度和不同语义级别的视觉特征表示。为了提高网络的收敛能力,UNet++解码块的全卷积模块改为残差模块。并且在解码块之前加入注意力机制,以减少数据不平衡的影响。为了充分利用每个层次的特征图,并且进一步改善输出结果图的精度,通过输出融合不同层次的特征图来提高空间细节。每层输出都与一个混合损失函数相连,提高特征图的精度。最后,一个sigmoid层生成最终的变化检测结果图。
2.1 孪生卷积网络编码块
建筑物变化检测的目的是检测不同时间同一区域的多时相遥感图像之间具有“语义变化”的像素。实际上就是对多时相的像元进行分类,高分辨遥感影像信息量很丰富,对特征的提取要求更高,所以这里选择孪生全卷积神经网络作为编码器,如图2所示。编码器的结构为Siamese-Differenc[14]结构,通过对网络的两个分支对图像分别进行处理,提取双时相图像中的多尺度特征,两个分支网络具有相同的结构,并共享参数。具体即两个时相的遥感影像分别输入编码网络的两个分支,两个分支分别输入的是RGB三通道图片,两个分支每个编码块由两个卷积层、一个池化层组成,卷积层可以从输入图像中提取层次特征。池化层的功能包括感受野扩大和降维,用于聚合特征。每个编码块在第二层卷积层取建筑物特征后,将两个分支的特征图相减后取绝对值作为这一层的输入即xi,0。
2.2 残差网络解码块
原始的UNet++网络结构,不同阶段的特征图直接叠加,并且没有使用全局上下文特征来区分各种类别。而残差模块[15-16]利用残差结构对抽象特征进行细化,提高特征的抽象表达能力。同时,残差模块避免了网络层数过多导致梯度消失和网络退化的问题。残差模块如图3所示。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
2.3 注意力机制
注意力机制[17]可以用于图像语义分割。通过矩阵算法,注意力机制可以理解为任意两个位置之间特征图的合作。因此,可以在不增加计算和存储成本的情况下对远程依赖进行建模。在UNet++跳跃连接添加一个注意力机制,注意力的流程图,如图4所示。注意力机制的输入为上采样的特征图和横向跳跃连接特征图,上采样的特征图用作门控信号,以提高在分割任务中建筑物的学习能力,同时抑制无关的背景区域。因此,注意力机制可以通过跳跃连接来提高生成语义信息的效率。此外,选择激活函数Sigmoid来训练收敛性,得到注意力系数α。然后,通过编码器特征,通过系数α像素与像素相乘得到输出。
2.4 输出深度监督
UNet++网络结构有四个不同尺度特征图的输出,浅层特征图捕捉的是丰富的空间信息,突出建筑物的边界,而深层的特征图则体现建筑物的位置信息,为了能够充分利用多尺度的特征图,提出深度监督[18]的特征融合方法来结合变化检测多尺度特征图的低级语义和高级语义。深度监督的策略类似UNet3+[19]提出的全尺度深度监督。具体监督方式如图1所示,对于四个输出节点[{x0,1,x0,2,x0,3,x0,4}],四个节点后面跟着一个sigmoid层得到边输出结果[{y0,1,y0,2,y0,3,y0,4}]。然后,可以通过四个侧输出结果来生成一个新的输出节点[x0,5]:
[x0,5=y0,1⊕ y0,2⊕ y0,3⊕ y0,4] (1)
其中⊕表示连接操作。同样,x0,5之后是sigmoid层,因此可以生成融合输出y0,5。因此,在深度网络中产生了五个输出,来自所有侧输出层的多级特征信息被嵌入最终输出y0,5,从而能够捕获更精细的空间细节。
2.5 混合损失函数
不平衡问题在深度学习任务中很常见。对于遥感影像变化检测,变化样本和不变样本的数量差异很大。在许多情况下,变化像素只占图像总像素非常小的百分比,会在训练阶段导致网络出现一些偏差。为了削弱样本不平衡的影响,使用了一个混合损失函数。该混合损失函数基于二进制交叉熵损失函数(BSE) 和骰子损失函数(Dice Loss) , Dice Loss相当于从全局上进行考查,BSE是从微观上逐像素进行拉近、角度互补。
提出的改进UNet++网络结构,在sigmoid 层的分类器之后生成了五个输出层。假设相应的权重表示为wi(i = 1, 2, 3, 4, 5)。然后,整体损失函数L可以定义为:
[L=i=15ωiLi] (2)
其中Li(i = 1, 2, 3, 4, 5) 表示来自第i个输出的损失,它通过结合二元交叉熵损失函数和骰子系数损失来使用:
[Li=Libac+λLidice] (3)
其中Lbce表示二元交叉熵损失,Ldice是骰子系数损失,λ是指平衡这两个损失的权重。
2.5.1 二元交叉熵损失函数
基于卫星图像的变化检测任务,变化/未变化像素的分布存在严重偏差。特别是某些区域仅被改变或不变的像素所覆盖,导致在深度神经网络训练过程中出现严重的类不平衡问题。因此,必须为有偏采样引入权衡参数。在端到端训练方式中,损失函数是在训练图像的所有像素上计算的:
[X=xi(i=1,2,…,|X|)] (4)
[Y=yj(j=1,2,…,|Y|)] (5)
其中X表示输入图像,Y表示输出层图像,并且yj∈{0,1}。采用简单的自动平衡策略,二元交叉熵损失函数可以定义为:
[Lbac=-αjεY0logPr(yj=0)-βjεY1logPr(yj=1)] (6)
其中Y0表示遥感影像标签中未变化的像素,Y1示遥感影像标签中变化的像素,其中[α=Y1Y0+Y1],[β=Y0Y0+Y1],Pr(.)是像素j处的 sigmoid输出。
2.5.2 骰子系数损失函数
为了提高分割性能并削弱类不平衡问题的影响,通常在语义分割任务中应用骰子系数损失。一般来说,两个轮廓区域的相似度可以用骰子系数来定义。此外,骰子系数损失可以定义为:
[Ldice=1-2YYY+Y] (7)
其中Y和Ŷ分别表示训练图像对的预测概率和真实变化的标签。
3 实验和结果
3.1 数据集LEVIR-CD
数据集LEVIR-CD[11]包括637个超高分辨率的Google Earth双时相遥感图像对组成,每幅图的大小为1024×1024像素,空间分辨率为0.5米。这些双时相图像来自美国得克萨斯州多个城市的20个不同地区,数据集涵盖了各种类型的建筑,例如别墅住宅、高层公寓、小型车库和大型仓库。该数据集的建筑物变化不仅包括建筑物的消失,也包括建筑物的更新和建筑物无变化的样本。LEVIR-CD数据集分为train、val和test三个部分,分别有445、64和128对。
3.2 实验环境和设计
本文实验运行环境为Windows,平台为11GB显存的GPU(RTX2080Ti) ,采用Python3.6语言,PyTorch框架。训练选用Adam优化算法,batchsize为8,学习率为0.0001,epochs为200,耗时5h。