网罗千象,析其机要
作者: 陈凯
摘要:通过设计特定任务让学生亲身体验数据采集、整理、处理和分析的全过程,对于促进学生深刻理解机器学习算法、提升信息技术核心素养是有益的,然而,现场采集标本建立数据集的活动在频率、范围及适应学生多样性等方面存在挑战。因此,本文提出可以利用网络,在线进行数字化标本的搜集整理来构建数据集,并介绍了三个基于在线数字化标本搜集整理的机器学习实验项目:利用线性分类来分辨早开堇菜和紫花地丁这两种植物图像、基于K近邻算法分辨公园和居民小区卫星图像,以及构造决策树来分辨玄武岩和流纹岩的图像。这些项目展示了在线标本采集的便捷性和高效性,为学生提供了更加丰富多样的学习体验,同时提高了数据集的构建效率,更为方便地展现出不同的机器学习算法对于不同种类数据的适用性。
关键词:实验教学;人工智能教学;在线标本;数据集;生成式人工智能
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2025)07-0015-05
在人工智能实验教学开展过程中,设计特定任务让学生亲身体验数据采集、整理、处理和分析的全过程,不仅能够提高观察能力、动手能力和数据处理能力,还有助于让学生更好地理解和应用机器学习算法。尽管如此,现场采集标本并建立数据集的活动在适应学生多样性的自主学习和研究性学习方面却面临很大的挑战:不同学生拥有不同的兴趣点、学习节奏和偏好,现场采集活动往往难以兼顾所有学生的个性化需求;受学生活动范围、时间及技术水平的制约,能够在自然环境中现场采集获得并用于较为基础的人工智能实验的数据种类是相当有限的,较难体现出机器学习作用的普遍性,也较难体现出不同机器学习算法对不同数据的适用性;此外,现场采集活动通常需要大量的时间和资源准备,这在一定程度上限制了活动的频率和范围,限制了组织实验教学的灵活性。相较于现场采集,利用网络在线标本搜集整理来构建数据集,虽然在具身体验上有所欠缺,但能展现出独特的便捷性和高效性。下面,笔者通过三个例子,介绍基于在线标本搜集整理任务的机器学习实验项目,并归纳此类实验任务的优势。
从早开堇菜和紫花地丁的分辨到线性分类
早开堇菜和紫花地丁都是堇菜科堇菜属的多年生草本植物,它们都在早春时节开花,花和叶子的形态非常相近,很容易认错。但两者有一个大概率存在的区别,就是花的颜色有微妙的不同。网络上的资料在提及分辨方法时,一般会说,紫花地丁的颜色比早开堇菜略深一些,但实际上,只凭借这样的信息,仍然不容易区分早开堇菜和紫花地丁,因为无论是早开堇菜还是紫花地丁,不同植株花的颜色深浅在整体上是有所不同,如果以灰度为深浅标准,早开堇菜的花色也常常深于紫花地丁。如果勉强要用语言描述,只能说,早开堇菜的花色更接近于木槿的堇色,而紫花地丁的花色更接近紫水晶的堇色。
有理由猜测,早开堇菜的花色的RGB值,即红色、绿色和蓝色的亮度值,和紫花地丁的花色的RGB值,有各自独特的内在的比例关系。如果能够采集到较多的两种花的颜色数据,然后对颜色中的R值、G值和B值与花的种类关系进行线性分类,并根据分类的模型对测试数据进行验证,如果此分类模型识别正确率高,则说明以上猜想是正确的,同时也说明,通过对两种花的颜色的RGB值进行线性分类来区分早开堇菜和紫花地丁是可行的。
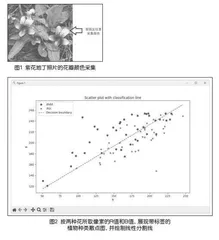
数据采集可以在“中国植物图像库”等较权威的植物图像网站进行,这些网站通常提供了同一植物物种在不同地域的记录照片。在网站上可以看出,即便是同一种花,花瓣的颜色差异也是很大的,如标本号1635352、3354151、137973、105646这四株紫花地丁花瓣颜色直观感受有着明显不同。在采集过程中,可以规定所要采集的颜色固定在花的某个位置,比如说,可以取5枚花瓣中上方花瓣的尖锐处边缘部分颜色,并避开深色纹路,而不采集朝向下方的唇瓣的颜色(如图1)。作为对照,也可以随机选择花瓣不同部分采集颜色,经实验证明,如果数据足够多,并且避开颜色过浅过亮的区域,即便是随机选择花瓣的区域采集颜色,对最终分类结果的影响也并不是很大,这是因为虽然花瓣各处颜色深浅有较大差异,但颜色RGB值的比例仍然保持着一定的关系。由于采集工作可以由全体学生集体实施,采集方法也很简单,所以很快就能获取大量数据。
利用生成式人工智能以及Scikit-Learn库,能够很方便地生成线性分类程序代码。可以尝试按颜色RGB值中R值和G值、G值和B值、R值和B值不同的组合来进行线性分类,通过分割训练集和测试集,检验分类效果。经实验,发现对R值和B值数据进行线性分类效果最好,正确率可达70%左右。
如果按两种花的所取像素的R值和B值数据绘制出带种类标签的散点图(如图2),可以直观地显现出,何以线性分类是有效的,同时也能看出,有少部分早开堇菜和紫花地丁的颜色的确是难以分辨的,这也就是线性分类正确率有限的原因。
从公园和居民小区的分辨到K近邻算法
在线卫星地图是另一种较为容易获得图像标本的平台。考虑这样的任务:基于K近邻算法构造模型,使之能够在城区中分辨公园和居民小区。实验可以按以下步骤进行:
①在卫星地图上分别截取不同的公园和居民小区的图像,按公园和居民小区分别进行标注,如公园图像文件名均以P开头,居民小区图像文件名均以R开头;
②将图像裁剪到同样的尺寸,如80*80像素,可以利用生成式人工智能生成程序代码来实现图片的自动裁剪,产生的图片如图3所示;
③提取特定的图像特征信息,可以利用生成式人工智能来生成程序代码,实现特定特征的自动提取;
④按训练集中已提取的特征及已有标签,利用生成式人工智能生成代码,对测试集的图像基于K近邻算法进行分类。
在以上步骤中的第3步,需要考虑提取哪些图像特征更适合于K近邻算法的运用。可以优先采用一些比较简单也很容易理解原理的方法,如提取颜色、计算信息熵等,并且,这些特征也已经在信息技术必修模块中提及。当然,也不排除可以采用过滤器来提取边缘或纹理信息,但对于提取出来的边缘和纹理,如何转换成适合K近邻算法处理的数据,存在一定的难度。特征提取的方案具有开放性和多样性,较容易激发出学生构想不同的方案并进行进一步实验的热情——由于有了生成式人工智能的帮助,很多方案可以快速有效地验证其效果。例如,可以枚举图像中的像素,当某像素的灰度值大于110,并且该像素右侧的第5个像素的灰度值小于70的时候,则对计数器加1,由于居民小区中常常布局了有规律的成排房屋,通过这种亮暗匹配,计数器的值就会变得很高,虽然这个结论对少数别墅区并不成立,但有很大概率识别出较大型的成规模的居民小区,如图4所示。图5显示了基于像素中G值平均值高低和图像信息熵这两个特征值绘制的带标签的散点图,可以看出,居民小区的特征点集中在左上角和中间区域,公园的特征点则差不多集中在对角线上。通过图示可知,用K近邻算法,对卫星地图中的公园和居民小区进行分类是可行的。
在人们的想象中,公园的植物覆盖率高,像素颜色G值的平均值也应该高,但实际上,某些公园有大片水域覆盖,像素颜色中G值未必高于一些绿化较好的居民小区,不过,存在大片水域的公园图像整体信息熵也比较低。这个例子可以说明,采用K近邻算法,可以解决用线性分类难以解决的问题。具体的借助生成式人工智能生成K近邻算法,对训练集的数据进行处理并对测试数据进行预测的过程比较容易,已有大量资料可借鉴,这里就不赘述了。
从玄武岩和流纹岩的分辨到决策树
对非专业人士来说,岩石的手标本鉴定(现场采集岩石,仅仅依靠手眼鉴定的标本)是具有相当大的难度的,但是,如果对岩石大类进行限定,如限定在最为常见的喷出岩(岩浆经火山口喷出到地表后冷凝而成)的框架中,那么仅仅通过观察岩石的照片对岩石进行分类,就能够保证一定的成功率。例如,玄武岩和流纹岩在肉眼观察下可以通过颜色、外观、结构与纹理等特征进行区分,新鲜的玄武岩通常呈现暗色或黑色,氧化后可能变为紫红色,表面可能发育有气孔构造和杏仁构造,其结晶粒度较细,整体呈现均质结构,而流纹岩的颜色通常为灰色、浅灰色等,有时也可能呈现粉红色或砖红色,表面常见流纹构造,结晶粒度相对较粗,晶体较容易观察到,常呈现斑状结构,图6所示的是某玄武岩和某流纹岩的数字化标本图像。之所以选取这两种岩石,一个很重要的原因,就在于它们的形态差异相对明显。可以注意到,可以通过有或没有某种特征来区分玄武岩和流纹岩,并且,是否具有某种特征,与具有此特征的岩石究竟属于哪种岩石还存在着一定的不确定性,这就意味着,可以采用决策树的方法,来构建自动岩石识别模型。
在中国国家标本资源平台、国家岩矿化石标本资源共享平台提供了大量可供观察的数字化的岩石标本,以下是实验大致过程:
①教师从数字化标本资源平台随机选取玄武岩和流纹岩图片,隐去岩石种类标签,仅提供岩石编号;
②要求学生按编号观察岩石,并按特定的特征填写表格,记录岩石编号和特征,相对来说比较容易观察到的特征有是否有气孔、颜色是否深、晶粒是否细密等,教师结合岩石的种类标签,完成可供机器学习算法处理的数据集,图7显示了某次岩石数字化标本的数据采集的表格样式;
③基于决策树算法,利用生成式人工智能处理包含了岩石特征和岩石种类标签的数据集,生成能够构造决策树并通过决策树进行推理的代码。图8显示了对某一批数据进行处理所生成的决策树。
结论
在线标本采集不受地域和时间的限制,学生们可以轻松获取到来自世界各地的样本,为机器学习模型提供更加全面和多样化的训练数据。同时,在线标本通常经过了专业鉴定和分类,具有较高的准确性和权威性,这有助于减少数据集中的错误和噪声,提高模型的准确性。此外,利用计算机视觉库和自动化处理工具,学生们可以更加快速、准确地提取出标本的关键特征,提高数据采集和记录的效率。并且,部分在线采集任务也可以和信息技术必修模块中网络资源获取相关活动结合起来。在线标本采集不仅节省了时间和精力,还使得数据集的构建过程更加高效和可靠,同时也为学生们提供了更加丰富多样的学习体验。
然而,需要补充的是,真实环境下的现场数据采集仍然是重要且值得操作的,许多信息难以完全通过在线方式获取,现场数据采集能够提供更为真实、直观的样本信息,为学生提供领悟世界复杂性与解决问题多样性的具身体验。尤其在跨学科活动中,现场采集任务能让学生亲身体验数据的来源和背景,加深对相关专业知识的理解,不仅能锻炼学生的实际操作能力,还为更全面、更深入的思考和探索提供实践基础。因此,在线标本数据采集与现场数据采集应相辅相成,共同促进学生综合能力的提升。