车辆环境下基于生成对抗网络的推荐列表二次排序模型
作者: 彭二帅 孙一凡 李镇宇
摘要:针对现有车辆推荐算法在数据稀疏情况下推荐效果不佳,以及难以处理用户购买意图受多种因素影响的非线性关系问题,文章提出了一种基于生成对抗网络(GAN)的推荐列表二次排序模型(RGANV)。该模型首先利用门控循环单元(GRU)网络分析车辆用户的会话信息,生成初步推荐列表。随后,利用该列表训练GAN 模型中的判别器,并根据训练好的生成器对推荐列表进行二次排序,使商品相关性评分更加准确,进而生成高质量推荐列表。仿真结果表明,RGANV 有效解决了GRU 模型在车辆用户长期信息获取上的不足,并改善了多因素干扰问题,提升了推荐效果。
关键词:车载电商推荐; 门控循环单元; 生成对抗网络; 二次排序; 策略梯度
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2025)06-0088-03开放科学(资源服务)标识码(OSID):
1 相关工作
随着车联网技术的迅速发展,如何为车辆用户提供高效的推荐服务已成为学术界和工业界的热门研究方向。然而,推荐系统普遍面临着冷启动和数据稀疏等挑战。冷启动是指系统运行初期,可利用的车辆用户历史信息极其有限,难以进行精准推荐。为解决该问题,Gao等人[1]提出了一种基于多目标特征交叉的服务质量预测推荐算法。该算法通过词嵌入方法引入多目标特征,并利用神经网络实现特征的自动交叉,从而提升了算法在冷启动和数据稀疏场景下的推荐效果。
相比传统的个性化推荐算法,基于神经网络的方法能够挖掘更加复杂的非线性关系,因此备受关注。Liao等人[2]提出了一种基于图神经网络(GNN)的社交推荐方法。该方法考虑了用户感兴趣的不同物品之间的潜在相关性,并融合用户行为和辅助信息来建模用户偏好,以提高推荐的准确性。Jiang等人[3]针对传统神经网络协同过滤算法存在的建模复杂、训练效率低和数据稀疏等问题,提出了一种融合信任度与注意力机制的神经网络推荐算法。该算法将用户间的信任度值加入特征向量,并在神经网络模型中引入注意力机制,以增强关键隐式反馈信息的权重,从而缓解社交网络中数据缺失带来的影响。
本文提出的RGANV模型在GRU[4]模型的基础上进行强化训练,通过构建生成器和判别器,并利用两者之间的博弈训练来优化推荐效果。具体而言,RGANV使用策略梯度训练方法来提高正样本出现的概率,使商品相关性评分更加接近真实情况,从而生成更准确、高质量的推荐列表。RGANV模型本质上是对GRU模型推荐结果进行的二次排序。
2 推荐列表二次排序模型RGANV
本文通过使用一种提出的生成对抗网络模型RGANV对推荐列表进行重排序以提高推荐效果。下面本文将详细介绍该生成对抗网络模型的基本结构、构建方法以及训练流程。
2.1 RGANV 的模型结构
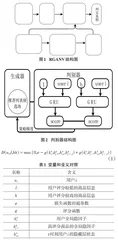
该生成对抗网络的具体结构如图1所示。对于生成对抗网络的构建,本文将混合推荐算法模型作为生成器。RGANV模型通过输入用户和商品的长期历史信息及短期会话信息,得到了一个初步的推荐列表。由于对称性有助于增强网络的鲁棒性,本文将判别器设置为一个共享参数的对称网络模型。判别器的输入数据和训练方式与生成器有所不同。
判别器的输入数据除了有生成器生成的数据,还有用户真实点击的数据和从低评分商品中随机抽取的低评分商品数据。判别器的能力提高了自然也就能更加成功地将生成器生成的数据与真实数据进行区分。训练完判别器后然后将其固定住,然后通过最小化生成器中生成数据与真实数据的差距对生成器进行优化。
RGANV模型中,生成器部分设置为第三章提出的RGANV网络。生成器的输入数据同第三章一样,包括用户对商品的点击流序列(商品id、time stamp)、点击某件商品的用户序列(userid、time stamp)和用户对商品的评分数据(用户全局隐因子和商品全局隐因子),输出模型为商品推荐列表。图1中的真实数据包括高评分商品和随机采样的低评分商品信息。
2.2 使用对称网络构建判别器
本文设计了一种共享参数的对称网络作为判别器,判别器的结构如图2所示。
图2中,h表示用户评分较高的商品信息,l表示用户评分较低的商品信息,判别器中的对称网络共享同样的参数,通过最小化损失函数进行更新。判别器的计算式化描述如式1所示,各个变量的含义如表1 所示。
2.4 RGANV 的训练过程
本文构建的生成对抗网络的具体训练训练过程如图4所示:
1)生成推荐列表。将用户和商品的长期历史数据和短期会话数据输入到RGANV推荐模型中,通过计算用户与商品间的相关性评分得出一个推荐列表。
2)判别器训练
步骤一:从之前计算的低评分商品中随机抽样输入到判别器,训练判别器区分低评分和真实高分数据的能力。
步骤二:将生成器生成的推荐数据输入到判别器,让判别器区分生成数据与真实数据之间的差别。
3)优化生成器。采用基于强化学习的策略梯度优化算法对生成器进行优化,如果一个动作的奖励值高则增加该动作的出现概率,反之则减小该动作的出现概率。
4)迭代计算。采用交替训练的方式对生成器和判别器进行迭代训练。固定住一方训练另一方,直到判别器的输出值接近0.5。这时,鉴别器无法区分真实数据与生成器生成的数据。
5)更新推荐列表。根据训练好的生成器,将之前生成的推荐列表中的数据通过训练之后的生成器重新排名。
3 实验结果与分析
3.1 实验环境配置及参数设置
将DIGINETICA数据集中不满足条件的数据采用和YOOCHOOSE数据集同样的标准过滤掉,最终保留了188300 条会话和38500 件商品。由于YOOCH⁃OOSE数据集的数据量表较大,训练起来比较困难,因此本文截取了其中的部分数据形成了1/3数据集和1/32数据集。数据集的总体情况如表2所示。
本文的实验是在Windows 11系统下基于Python3.6.2实现的,具体的实验环境配置如表3所示。
3.2 实验结果分析
本文使用实验数据集为RecSys 2015 YOOCH⁃OOSE数据集和CIKM Cup 2016的DIGINETICA 数据集。将使用生成对抗网络技术重新排序的推荐模型(记为RGANV) 与未使用该技术的GRU 模型进行对比实验。实验结果如表4所示。因为本文使用生成对抗网络技术旨在对GRU模型生成的推荐列表进行重排序,所以这里本文在平均倒数排名(MRR)上进行对比,默认推荐列表长度为20。
因为使用了生成对抗网络,对于商品相关性评分的学习,使得推荐列表中召回的商品位置更加靠前,所以,通过表3中的实验对比结果可以看出,通过生成对抗网络对RGANV模型进行强化训练后的推荐列表在平均倒数排名指标上有明显的提升,分别在YOOCHOOSE1/32 数据集上提升了4.3%、YOOCH⁃OOSE1/3数据集上提升了4.8%、DIGINETICA数据集上提升了5.2%。
图5和图6为在不同推荐列表长度情况下,RGANV 和GRU 在YOOCHOOSE1/32数据集和DIGI⁃NETICA数据集上的实验结果对比。图中,无横坐标为推荐列表的长度,纵坐标为MRR数值。无花纹的柱状图为GRU方法的推荐结果,带有花纹的柱状图为RGANV方法的推荐结果。
通过RGANV和GRU的对比实验结果图本文可以发现,在不同的推荐列表长度情况下,RGANV模型在两个数据集上均表现出了更加优异的成绩。在不同的推荐列表长度下,RGANV 对于平均倒数排名(Mean Reciprocal Rank,MRR)指标提升的程度不尽相同,在推荐列表长度为15到20区间提升最为明显。实验结果很好地验证了生成对抗网络在推荐列表排名优化问题上做出的贡献。
4 结束语
本文使用生成对抗网络技术对推荐列表进行二次排序的RGANV模型,使用了生成对抗网络,对于商品相关性评分的学习,使得推荐列表中召回的商品位置更加靠前。首先,介绍了生成对抗网络技术的基本原理及组成结构。然后,介绍了RGANV模型的基本框架结构,分别介绍了如何构建生成器与判别器。对生成器的更新方法-策略梯度进行阐述,给出了RGANV的训练过程。最后,通过对比实验验证该模型的优越性。实验结果表明,MRR指标得到了明显提升。在以后工作中,本文将尝试引入更多的因素,例如商品种类与价格之间的关联性,提高推荐的准确性。