基于视觉大模型的个性化反馈在大学生面试能力培养中的创新应用
作者: 陆苏于 王永固
摘要:本文介绍了一种基于视觉大模型的大学生就业面试多模态测评与训练系统。该系统通过多模态数据捕捉与分析,提供个性化的面试反馈,旨在提升大学生的面试技能。研究内容包括多模态数据采集、视觉大模型训练和系统功能设计。初步应用显示,该系统能够有效识别和分析面试者的非言语行为,如面部表情和肢体动作,为学生面试能力的提升提供了科学、个性化的支持。
关键词:大学生面试;多模态识别;视觉大模型;个性化反馈;面试训练系统
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2025)08-0101-05
随着每年大学毕业生人数的不断增长,就业市场的竞争愈发激烈。在这种背景下,面试技能越来越受到毕业生的关注。本研究旨在通过构建基于视觉大模型的多模态测评与训练系统,为大学生提供科学、个性化的面试训练工具,提升其面试表现和就业竞争力。
研究综述
多模态识别技术通过综合利用文本、视觉、听觉等多种信息来源,能够全面、准确地理解和处理复杂任务。该技术在情感计算、人机交互、视频监控等多个领域中都有广泛的应用。其基本原理在于综合使用多种信息来源,以提高信息处理的效果和可靠性。[1]
深度学习(Deep Learning)是由Hinton等提出的,是一种具有自动化、高效性、精确性和高灵活性的机器学习方法。深度学习模型拥有多种神经网络结构,包括卷积神经网络(Convolutional Neural Networks,CNN)、长短时记忆神经网络(Long Short-Term Memory Networks,LTSM)等。其中,卷积神经网络主要被应用于图像处理和人脸识别。[2]
随着深度学习技术的不断发展,当前,基于多模态识别的方法被广泛应用但存在一定的局限性:一是模态间关联性考虑不够,现有方法在处理多模态数据时,往往没有充分利用不同模态间的关联,导致信息的片面利用,降低了模型对整体数据的挖掘能力;二是个体间差异性考虑不足,每个人都具有独特的表情等非语言行为,这些个体差异对于精准识别至关重要,然而目前的方法个体差异性不强,导致个性化反馈机制不完善。
理论基础
1.多模态识别理论
多模态识别技术综合视觉、听觉等多模态信息,通过特征拼接、特征加权等方式将不同模态的特征合并,通过投票机制、加权平均等方式将不同模态的分类结果融合,通过集成学习方法将多个模型的输出结果融合,从而实现多模态融合识别。
2.教育心理学理论
情绪状态和非言语行为在面试过程中起着至关重要的作用,它们不仅影响面试者的表现,还会影响面试官的判断。积极的面部表情(如微笑、点头)、开放的肢体语言(如手势自然、坐姿端正)和坚定的眼神交流等非言语行为可以传达自信和诚实,反之则可能传递紧张和不安,影响面试官的评价。
3.社会呈现理论
Erving Goffman在其著作《日常生活中的自我呈现》中提出了社会呈现理论。该理论认为,人们会根据不同的社会场合和观众,调整自己的语言和非言语行为,以达到特定的社交目的。在面试过程中,面试者的行为一致性不仅影响其自身的表现,还会影响面试官的判断。面试中行为一致性的重要性在于它能够帮助面试者更好地管理自己在面试官心中的印象。根据Goffman的社会呈现理论,面试者需要在情绪状态和非言语行为上保持一致,以展示自己的自信、专业能力和良好态度,从而更容易获得面试官的认可和信任。因此,面试者在准备面试时,不仅要关注自己的言语内容,还要注意自己的情绪管理和非言语行为的表现。
研究方法
1.研究设计
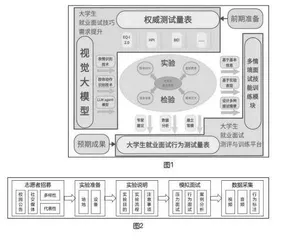
本研究的对象是面临就业的大学生。通过公开数据集、招募志愿者等参与实验,收集在模拟面试中的表现数据,以便对系统进行测试和优化。项目研究思路从理论研究、模型构建与优化、实验数据收集、软件开发到实际应用,逐步推进,确保研究的科学性和实用性,研究思路如图1所示。系统应用设计了多种典型的面试情境,如压力面试、行为面试、案例分析等,以覆盖不同类型的面试需求。
2.数据收集
(1)数据来源
①学院内部数据。利用学院已有的教学资源,如大小面试录像等,这些数据涵盖了不同专业、不同年级的学生在面试中的表现,具有较高的多样性和代表性。
②公开数据集。从公开的数据集中获取部分数据,如AffectNet(人脸表情识别数据集)、Kinetics(视频动作识别数据集)等,这些数据集提供了丰富的多模态数据,有助于模型的预训练和验证。
③志愿者数据。通过校园公告、社交媒体等方式招募志愿者,邀请他们参与模拟面试实验,利用高清摄像头和麦克风采集志愿者在模拟面试中的多模态数据,采集流程如图2所示。
另外,在归档存储前,对上述三类来源的数据,统一使用Python等工具进行预处理,包括去噪、格式转换等,确保数据的一致性和可用性。
(2)数据类型
①视频数据。记录面试者的面部表情、肢体动作等视觉信息。视频数据的分辨率设定为1080p,帧率为30fps,以确保数据的质量和清晰度。
②音频数据。记录面试者的语音信息,包括语音内容、语速、音调等。音频数据的采样率为44.1kHz,应用噪声减少功能,优化音频清晰度。
③文本数据。记录面试过程中的问题和答案,以及面试者的自我介绍等文本信息。
④标注数据。由心理学专业人士对面试者的非言语行为进行标注,包括表情、肢体动作、眼神交流等,用于训练和验证模型。
(3)数据管理
使用文件系统存储采集到的数据,包括视频数据、音频数据,使用数据库存储文本数据和标注数据。数据库设计应确保数据的安全性和完整性。因此,要采取必要的安全措施,如数据加密、访问控制等,保护数据不被未经授权的访问和泄露,并定期对数据库进行备份,防止数据丢失。
3.技术实现
(1)多模态捕捉识别技术
表情识别。①使用OpenCV库读取视频流,对每一帧图像进行预处理,包括灰度化、归一化等操作,以提高后续处理的效率和准确性。②使用深度学习模型(MTCNN)检测视频帧中的面部区域,提取面部特征点。③利用预训练的表情识别模型(FER2013数据集训练的ResNet模型)对提取的面部特征点进行表情分类,识别出高兴、悲伤、愤怒、惊讶等基本表情。
肢体动作识别。①使用OpenPose库或MediaPipe库对视频帧中的肢体进行姿态估计,提取关键点坐标。②利用卷积神经网络(CNN)和循环神经网络(RNN)组合模型(LSTM)对提取的姿态关键点进行时序分析,识别出不同的肢体动作,如挥手、点头等。通过预训练的动作识别模型(Kinetics数据集训练的3D ResNet模型)对提取的肢体动作进行分类,识别出具体的动作类别。
眼神交流识别。①使用深度学习模型(DeepGaze II)检测视频帧中的眼球位置,提取眼球特征点。②利用眼球特征点计算眼球的注视方向,判断面试者是否与面试官保持良好的眼神交流。
语音识别。①使用Librosa库读取音频数据,进行预处理,包括降噪、分帧、加窗等操作。②提取音频的Mel频谱图、MFCC等特征。③利用预训练的语音识别模型(Google的Speech-to-Text API)将音频转换为文本,提取面试者的口头表达内容。
(2)LLM agent模型
利用LLM agent模型提高传统动作识别的准确度,实现多方面、立体化的多模态输入。选择预训练的大型语言模型(LLM),本研究选择通义千问的开源模型,该模型具有强大的语言理解和生成能力。利用LLM agent模型的生成能力可以生成更多的训练数据,增强模型的泛化能力,生成多样化的面试场景,包括不同类型的面试问题、面试官的反馈等,将生成的面试场景应用于系统中,为用户提供更加真实和多样化的面试训练环境;利用其语言理解能力可以对面试者的动作进行深入理解,识别出动作背后的情感和意图,对面试者的动作进行更准确的分类和评估,识别出积极、消极、中性等情感状态,生成个性化的反馈报告,指出面试者在情感表达方面的优点和不足,并提供改进建议。其在本系统中的作用如图3所示。
4.系统架构
本系统是一个基于多模态数据捕捉与分析技术的大学生就业面试模拟训练系统,采用B/S架构,旨在通过科学、个性化的训练和反馈提升大学生的面试技能。系统主要由前端、后端和数据库三部分组成,各部分之间的交互和数据流如下页图4所示。
结果与讨论
1.应用结果
(1)数据收集与预处理
目前,本研究已经整合了笔者所在学院内部的教学资源数据和公开数据集,使用了大小面试录像等内部数据,以及AffectNet、Kinetics等公开数据集,并对数据进行了去噪、格式转换等预处理工作,确保了数据的一致性和可用性。
(2)模型训练与验证
利用处理后的多模态数据训练了深度学习模型,该模型能够准确地识别面试者的非言语行为,并对其面试表现进行评估。本项目在大模型的训练中将面试中常见的肢体动作概括为中性动作、指向性动作、双臂交叉、双手合拢、双臂张开、未知动作六种。
在表情的训练中,本项目按照心理学上常用的情绪分类将面试者的情绪检测分为愤怒、厌恶、恐惧、开心、悲伤、惊讶、中性、紧张八种。
此外,本项目还增加了对语音识别的处理及自动标注功能,包括但不限于语义及表达情感的识别。模型训练采用了端到端的多模态学习框架,结合了视觉、音频和文本数据,提高了模型的综合评估能力。具体成果如图5所示。
(3)系统实现
本研究实现了面试场景模拟、自动评分、个性化建议等功能的开发。此外,系统在管理端还增加了训练数据管理和测试数据管理的功能,允许管理员上传和管理训练数据,确保数据的多样性和质量,允许用户上传自己的面试录像或音频,用于测试系统的评估能力。
2.系统功能
系统由前端和管理端两大模块组成,其具体内容如下页图6所示。
①面试场景模拟。系统能够根据用户选择的职业方向和岗位要求,模拟真实的面试环境。
②实时反馈。在模拟面试过程中,系统能够实时捕捉用户的非言语行为(如面部表情、肢体语言)和言语行为(如语音内容、语速、音调),并给出即时反馈。
③自动评分与报告生成。在面试结束后,系统将根据用户的整体表现自动生成评分报告,报告中包含对面试技巧的具体评价和改进建议。
④个性化辅导。基于用户的面试报告,系统提供针对性的学习资料和练习建议,帮助用户进一步提升面试能力。
⑤训练数据管理。管理员可以通过用户界面上传和管理训练数据,确保数据的多样性和质量。
⑥测试数据管理。管理员可以上传自己的面试录像或音频,用于测试系统的评估能力。
⑦测试结果纠错。管理员可以对系统的评估结果进行人工校正,系统会根据这些反馈不断优化模型,提高评估准确性。
3.用户反馈
在系统开发完成后,项目组向所在高校学生投放了问卷调查清单,有97人次参与了此次问卷调查,收到了以下反馈:81%的用户普遍认为系统的模拟面试功能非常接近真实面试场景,有助于减轻实际面试时的压力;66%的用户认为实时反馈和自动评分功能是非常有用的工具,能够帮助用户及时发现并改正不足之处;40%的用户提出希望增加更多职位类型的面试场景选项。
4.结果分析
系统通过现有的多模态数据分析技术,特别是在加入了语音识别和情感分析后,能够更全面地评估用户的面试表现。模型在非言语行为和言语行为的理解上都展现出了较高的准确率,这对于提升面试官的好感度和沟通效果至关重要。目前,模型的准确率已经从65%提升到了73%左右。
结语
本研究初步证明了利用多模态数据支持下的模拟面试训练对提高大学生面试技能具有有效性。系统在以下几个方面展现了创新性和实用性:①系统将视频、音频和文本数据进行了多模态融合,提供了更全面的评估视角。②建立实时反馈机制,帮助用户及时调整和改进。③基于用户的面试报告和自动评分报告,进行个性化的辅导。④系统能够根据用户选择的职业方向和岗位要求,模拟真实面试场景,帮助用户提前适应实际面试场景,从而可以有效服务当前大学生就业困难的社会问题,为高校在就业方面的工作提供了一个智能化的教学方案。当然,本项目在取得初步成功的同时,也仍存在一些限制,如数据量有限、模型泛化能力不够、用户经验局限、系统功能需进一步验证等。后续,笔者将在数据收集、优化模型、增加场景和职位类型、长期跟踪研究等方面展开进一步研究与实践。
参考文献:
[1]翟雪松,许家奇,王永固.在线教育中的学习情感计算研究——基于多源数据融合视角[J].开放教育研究,2022,28(09):43-54.
[2]杨婷婷.基于视频图像的人脸面部表情快速识别研究[J].计算机仿真,2024,41(04):67-72.
作者简介:陆苏于,研究方向为智能教育技术、人工智能教育应用、多模态数字人;王永固,通讯作者,博士,教授,研究方向为学习科学与技术、智能教育。
基金项目:2024年国家级大学生创新创业训练计划项目“基于视觉大模型的大学生就业面试多模态测评与训练系统研究”(项目编号:202410337038)。