基于动态深度可分离卷积的小目标检测模型
作者: 李克 刘战东 丁男 李海芳 付总礼
摘要:针对普通卷积模型无法满足小目标检测中更加有效的图像特征提取的需求,提出一种基于动态深度可分离卷积方法改进的YOLOv5轻量化目标检测模型。模型结合动态深度可分离卷积,通过4个不同的检测尺度对多层目标特征进行深度融合;在参数量和计算量都明显减少的情况下,改进后的模型性能效果提升显著。在公开数据集VOC上的实验显示,改进的模型DD-YOLO,在轻量级下比YOLOv5模型的性能提升1.7% AP,最佳性能AP50为89.2%,AP为71.2%。
关键词:小目标检测;特征融合;动态卷积;YOLOv5
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2025)09-0001-04
0 引言
在目标检测任务中,小目标检测面临着诸多挑战,这些问题主要源于现有检测模型与图像处理技术的局限性。卷积神经网络作为目标检测的核心模型,其通过卷积操作提取图像特征的机制存在不足。卷积操作虽能有效整合图像中的关键信息,但在执行过程中,图像尺寸的缩减不可避免。这一尺寸变化虽对大目标影响较小,却对小目标造成了致命打击。小目标在图像中本就占据有限的像素区域,尺寸的缩小进一步压缩了其特征表达的空间,使得原本就微弱的特征信号变得更加难以捕捉。小目标检测的困难问题主要集中在卷积操作导致的图像尺寸缩减以及下采样过程中的特征信息丢失。这些问题限制了目标检测技术在实际应用场景中的广泛推广与有效应用。因此,小目标检测对目前的通用目标检测模型提出了更高的要求。
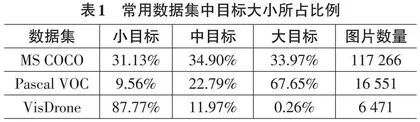
依据MS COCO[1]的界定标准,面积不足32像素× 32像素者归类为小目标,介于32像素×32像素至96 像素×96像素之间的目标为中目标,而超过96像素× 96像素的目标则被划分为大目标。VisDrone数据集中小目标占比高达87.77%,中等目标占11.97%,大目标仅占0.26%。 VisDrone数据集中大量密集的小目标显著制约了通用目标检测器的效能。以流行的YOLOv5目标检测网络模型为例,YOLOv5s在COCO数据集上AP值为36.6%,但在VisDrone数据集上AP值骤降至18.0%,仅为前者的一半左右,远低于MS COCO数据集上YOLOv5模型的性能表现。
本研究针对小目标检测尺度、动态特征提取等方面对YOLOv5网络模型进行研究,首先增加一个新的特征提取路径,原模型中Neck网络使用三层的PANet 特征金字塔进行特征的融合增强,分别是1 024、512 和256 像素,在此基础上增加了一条128像素的feature-level特征融合路径,用于针对小目标的检测。
其次,结合动态深度可分离卷积(Dynamic Depth-Wise Conv) 重新设计YOLOv5网络模型的基础结构,替换C3层中的一个普通卷积得到C3DDW模块,该模块结合动态深度可分离卷积对新的特征融合路径上的特征进行更加有效的特征提取,并通过更大的卷积核尺寸实现类似Transformer[2]结构中的全局感受野。使用CA(Coordinate Attention) 注意力机制来帮助模型学习到更加感兴趣的目标,在实验中发现,CA注意力机制可以一定程度上减少模型的计算量,并提升模型的推理速度,使模型推理速度更加接近实时。最终得到的YOLOv5改进模型的性能在Pascal VOC[3]数据集上达到89.2%的mAP和71.2%的AP。
1 模型设计
1.1 DD-YOLO 网络模
型设计在目标检测领域,尤其是小目标检测方面,研究者们面临着一系列挑战。为提高小目标的检测性能,近期的研究提出了多种改进方案,目前大多数研究者都使用数据增强、多尺度特征学习、上下文特征学习等方法。数据增强的方法是通过对原始的数据进行一系列变换,来提高模型的泛化能力,同时也可以增加训练的数据量;多尺度特征学习方法中,许多研究通过引入额外预测头,以针对小目标提供更高分辨率的特征图,从而增强小目标的预测能力,有些研究则使用增加隐藏层、改变特征融合方法和增加注意力机制的方式[7-10],对小目标物体的特征进行有针对性的提取[11-12];上下文特征学习方法则是通过提高模型的感受野,将全局特征融入局部,从而实现小目标物体的检测[13]。
本研究采用多尺度特征学习与上下文特征学习相结合的方式,对小目标检测中存在的微小物体难以检测到的问题进行研究,研究表明,提出的结合动态深度可分离卷积的多尺度上下文特征学习模块对于小目标的检测有较好的效果。研究中的基准模型使用ultralytics团队2020年公开的YOLOv5网络模型,模型总体结构如图1所示。
YOLOv5和YOLOv4[14]网络都使用了自适应锚框的方法,在目标检测网络中经常会对原始图片的尺寸进行缩放,因此在每一层可能图片中的物体大小都是不同的,锚定框的作用是对不同尺寸下的图像中的物体进行检测框大小的设定,使其更加贴近图像中的物体大小。YOLOv5还使用Mosaic、缩放和色彩空间调整等数据增强方法,引入PANet[15]双向特征金字塔网络,相比FPN[16] 的单向特征金字塔更具优势,相比较于其他模型,YOLOv5具有模型尺寸非常小,易于部署的特点,同时还具有训练速度非常快的优势(由于YO⁃ LOv5模型作者在不断更新,这里使用的YOLOv5是2021年6月份时候的5.0版本)。
在BackBone的最后和检测头之前,本研究使用C3DDW模块来加强特征提取,聚合有效特征,通过动态深度可分离卷积中的动态权重来实现重要特征的定位和提取,并通过大卷积核以及深度可分离卷积中的感受野优势来实现类似Transformer的全局感受野,达到局部连接、全局感受的优势,最后增加了一个检测头以针对小目标的检测。
在C3模块中额外增加了动态深度可分离卷积模块的连接,并用注意力机制整合全局上下文的特征信息
动态深度可分离卷积是对深度可分离卷积的改进,相比于深度可分离卷积,动态深度可分离卷积具有两个重要特点:一是可以实现权值共享——深度卷积在空间位置共享连接权值(核权值),而注意力在通道之间共享连接权值;二是使用动态权值计算方式——局部注意力基于局部窗口中两两位置之间的点积,而动态卷积基于在中心表示或全局池表示上进行的线性投影。
深度可分离卷积(Depthwise Separable Convolu⁃ ttiioonn[,4]D和SCM)o 最bil早eN在et[一5]两篇个博著士名论的文网中络被模提型出结,后构来让X深ce度p⁃可分离卷积被大众所熟知,深度可分离卷积是一种将不同通道的特征分别进行卷积的操作,首先它将不同通道的特征图分离,并分别使用不同的卷积核对其进行卷积操作,最后将这些卷积后的输出拼接起来得到最终的输出。
Qi Han等人[6]将Transformer模型中的局部注意力重新表述为一个基于信道的局部连接层,并从稀疏连接和权值共享两种网络正则化方式以及动态权值计算两方面对其进行分析。对深度可分离卷积进行深层次的研究,通过增大卷积核尺寸和动态权值共享的方式基本实现Transformer模型中的局部注意力特点,包括稀疏连接、参数共享、动态权重和集合表征等。本研究将动态深度可分离卷积与多尺度特征学习结合,对小目标物体进行更细粒度和多层次的特征学习和提取,达到了良好的小目标检测效果。
本研究在 C3DDW(C3 with Dynamic Depth Wise Conv)模块中引入动态深度可分离卷积作为额外的特征提取器,对于每个通道维度,动态深度可分离卷积都分别生成一个单独的卷积核来对其进行卷积操作,但是这些不同的卷积核权重都是共享的,在每个单独的卷积开始之前,通过平均池化和点卷积的操作来学习生成一个动态的权重,随后将每个通道维度分为一组,使用生成的动态权重分别对每组的特征进行卷积操作,这样就完成一次动态深度可分离卷积的过程。在特征提取器工作完成之后,将CSPBlocks 模块和DDW Conv模块所提取的特征拼接起来,并使用一个注意力机制进行全局上下文特征整合,增强有效特征,为了与整体网络结构保持一致,在最终输出之前增加归一化层和SiLU激活函数。
式中:GAP是全局平均池化操作符,用于将输入特征图的每个通道压缩为一个标量值,g 代表线性投影的函数,通常是一个全连接层或线性变换,用于将全局平均池化后的特征映射到卷积核权重空间,x 是特征图中的不同特征向量,通过 x 分别预测每个位置的卷积权重。通过这种方式,卷积核权重可以根据输入特征图的内容动态生成,而不是固定的,能够根据输入的不同自适应地调整权重,从而增强模型的表达能力。
2 实验分析
2.1 数据集及实验细节
本研究在具有挑战性的目标检测公开数据集VisDrone和PASCAL VOC进行实验和验证。所有实验都使用在COCO数据集上预训练过的YOLOv5模型权重。训练采用随机梯度下降优化器,类别为各个数据集所有类别。在进行实验时,其他设置不变,C3DDW模块中的卷积核大小设置为7,使用Idynamic 动态权重,本研究中Idynamic动态权重计算使用C语言实现,具有更轻量级更快的优势,而且性能也会略有提升。评估指标以AP50和AP为基准。
AP50与mAP同样是IoU = 0.5时的AP 分数,实验中以AP50来表示。
2.2 实验
2.2.1 消融实验
如表2所示,在使用动态深度可分离卷积cCa3lD VDOWC模数块据时集,上在相Pa比s⁃于基准模型获得了1.2%AP 的提升,同时其他三项指标精确率(Precision) 、召回率(Recall) 、IoU = 0.5时的平均精度(AP50) 也都获得一定的提升,表示动态深度可分离卷积在s尺寸的小模型下依然有着良好的特征提取和特征表达能力,在加入CA注意力机制后,模型的召回率和平均精度得到进一步加强,同时精确率和IoU=0.5时的平均精度略微下降,充分体现了注意力机制聚焦有效特征的特点,帮助模型关注有效特征,因此召回率得到进一步加强。
如表3所示,与m尺寸的基准模型相比,提出的方法在所有指标方面都有全面的提升,而且提升幅度都超过了1%,其中精确率大幅提升了2.38%,同时FPS 也提升了1.9,推理速度更快,此外,与同为YOLOv5基准的MCANet[17]方法相比,提出的方法虽然召回率和FPS小幅下降,但是在精确率、IoU=0.5的平均精度和平均精度AP三个指标都有不小幅度的提升,总体来说更具有优势。
如图4所示,第一行三张图片中,表明提出方法在海洋、陆地等各种不同场景下都有很好的检测结果,第二行场景中,在目标之间有一定遮挡的情况下也能够精确识别自行车、摩托车和骑车的人,最后一张图中,在夜间和密集目标的情况下,能够识别出大部分的车辆目标,包括较远的图片中像素很小的车辆也能识别出一部分,表明DD-YOLO模型对于各种场景、多种目标情况和小目标的识别检测能力。
2.2.2 与其他模型的对比
如表4所示,在VisDrone test小目标数据集上,提出的方法相比于基准模型在精确率、召回率、IoU=0.5 的平均精度和平均精度AP四个重要指标上都获得大幅提升,与HIC-YOLOv5模型相比具有接近2%的性能优势,同时与MCANet的模型相比也具有一定的优势,在四个指标上都优于MCANet,相比于最新的模型CRL-YOLOv5 较低的召回率38.7,其他指标相差不大,说明DD-YOLOs在四个指标方面都更加均衡,这充分说明本研究中设计的基于动态深度可分离卷积的网络模型更具优势。
在Pascal VOC数据集上,DD-YOLO与其他模型进行了定量的性能对比,如表5所示,与CVPR2018的SNIPER模型相比, DD-YOLO具有较大的领先,相比较于目前Pascal VOC 数据集上的最佳性能的方法MCANet(使用空洞卷积) 和CVPR 2021的Cascade Eff 模型,DD-YOLO模型在AP50性能上基本达到同一水平,同时在平均精度AP性能上领先MCANet模型,达到了71.2%的水平。
3结论
研究提出了基于动态深度可分离卷积改进的 DD-YOLO 目标检测模型,在 VOC 数据集上展现了显著优势,具有计算量小、参数量少、推理速度快的特点,同时在轻量级设置下性能接近 SOTA 水平。动态深度可分离卷积通过动态生成卷积核权重,增强了模型的特征提取和表达能力,并通过全局感受野的特征连接提升了多尺度目标检测能力。研究发现动态深度可分离卷积对有效特征提取和表达、全局感受野的特征连接具有重要意义,未来研究将进一步探索动态卷积核尺寸与感受野的关系、优化动态权重生成机制、扩展多任务学习与跨领域应用,并研究硬件加速与部署优化,以推动动态深度可分离卷积在目标检测及其他计算机视觉任务中的广泛应用。