基于改进Apriori算法的社交网络兴趣推荐系统研究
作者: 周华乔 孙一凡 乔琪 倪敬一 王康伟 祝宏亮
摘要:针对传统Apriori算法在处理大数据时效率低、资源占用大的问题,提出了改进措施。通过根据用户兴趣标签的频率动态调整支持度阈值,挖掘更具代表性的频繁项集,提高了算法的针对性和实用性。同时,引入并行计算,利用多线程技术加速候选项集的生成和筛选过程。将计算任务划分为多个并行子任务,显著提升了数据处理效率。改进后的Apriori算法在社交网络兴趣推荐系统中得到了应用,该算法不仅缩短了候选项集生成与频繁项集筛选的时间,而且在相同支持度阈值下,有效降低了误检率和漏检率,一定程度上提升了数据挖掘效率及推荐准确性。
关键词:Apriori算法;动态支持度阈值;并行计算;网络兴趣推荐系统
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2025)09-0009-05 开放科学(资源服务) 标识码(OSID) :
0 引言
随着社交网络的迅猛发展,涵盖用户点赞、评论、分享等行为信息的海量兴趣数据在平台上不断累积[1],这些数据无疑构成了深入洞察和挖掘用户偏好的宝贵资源。因此,如何高效利用这些数据,实现为用户量身打造的个性化推荐[2],已成为当前推荐系统研究领域的前沿热点。传统的推荐系统主要分为三大类别:基于内容的推荐[3]、基于协同过滤的推荐[4]以及基于关联规则的推荐[5-6]。基于内容的推荐系统通过分析用户历史行为与内容特征的关联,为用户推荐相似内容[7]。但这种方式存在冷启动问题,在处理新用户时存在局限性,且难以捕捉用户兴趣的变化。基于协同过滤推荐则侧重寻找行为相似的用户群体,据此为用户推荐他们可能感兴趣的内容[8],这种方式虽能发掘用户的潜在兴趣,但在数据稀疏的情境下表现欠佳,且计算复杂度相对较高。基于关联规则的推荐方法则是通过挖掘数据中的频繁项集,生成关联规则以进行推荐[9],这种方法能够产生多样化的推荐结果,但其初始阶段的计算量庞大,且对数据量有较高要求。在众多关联规则挖掘算法中,Apriori算法[10]得到了广泛应用。它通过生成候选项集与剪枝两个核心步骤,有效地挖掘出数据集中的频繁项集,并据此生成关联规则。然而,在处理大规模数据集时,传统Apriori算法暴露出效率低下的问题[11]。这主要体现在生成庞大的候选项集以及多次扫描整个数据集上,这些操作消耗了大量的内存空间和计算资源。
本研究的核心目标是对传统的Apriori算法进行改进,以提升其在社交网络兴趣推荐系统中的应用效能。为实现这一目标,将采取多项改进措施,包括动态调整支持度阈值[12]、引入并行计算技术来优化数据处理流程。这些改进旨在提高数据处理效率与挖掘准确性,从而为用户提供更为精准的个性化推荐服务[13]。通过这些技术手段,我们期望能够克服传统方法的局限性,推动社交网络推荐系统向更高效、更个性化的方向发展。
1 研究背景与相关工作
1.1 兴趣推荐系统概述
兴趣推荐系统[14]是现代信息技术的重要组成部分。其核心在于对用户历史行为数据的深入分析与挖掘。通过这一过程,系统能够精确地预测出用户可能感兴趣的内容,从而为用户提供个性化的推荐服务。精准地推荐不仅提升了用户体验,还增强了用户对系统的黏性和信任。
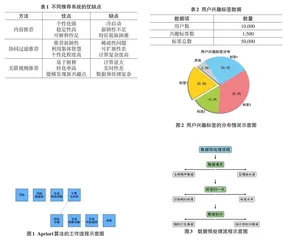
在现有的研究与实践中,为了更准确地捕捉用户的兴趣点,兴趣推荐系统主要采纳了三种核心推荐方法。首先,内容推荐深入分析用户历史行为与偏好,依据用户兴趣推送相似内容,实现个性化推荐。其次,协同过滤推荐通过寻找相似用户,推荐其喜爱内容,利用集体智慧拓宽推荐范围。最后,关联规则推荐挖掘内容间潜在联系,生成关联规则进行推荐,揭示不易直观发现的联系。这三种方法各有优势,相互补充,共同构成了提升兴趣推荐系统性能与准确性的重要基石。表1展示了不同推荐系统的优缺点。
1.2 Apriori 算法概述
Apriori算法是一种广泛应用于关联规则学习的算法,它通过两个核心步骤来发掘数据集中的频繁项集:生成候选项集与剪枝过程[15]。首先,根据用户兴趣数据生成候选频繁项集,然后通过计算支持度来筛选出实际的频繁项集,有效减少搜索空间。最后,根据频繁项集生成关联规则,并通过计算置信度来评估规则的有效性[16]。Apriori算法的工作流程如图1所示。
1)生成候选项集。
①设定最小支持度阈值。
②扫描数据集,生成所有可能的候选项集。
2)剪枝操作。
①计算每个候选项集的支持度。
②去除低于支持度阈值的项集,实现有效的剪枝,从而减少后续计算的复杂度。
3)生成频繁项集。
①重复上述的候选项集生成与剪枝步骤,不断地发掘出数据集中的频繁项集。
②无法再生成新的候选项集停止,最终得到满足最小支持度要求的频繁项集。
4)关联规则的生成与评估。
①获得频繁项集,算法进一步生成关联规则。
②对于每一条规则,计算其置信度。
③通过比较置信度与预设的最小置信度阈值,剔除置信度较低的规则。
④生成具有较高有效性和实用性关联规则。
2 数据收集与预处理
2.1 数据集描述
本研究涉及的数据来源于某大型社交网络平台。为保护用户隐私,所有数据在收集后均经过了严格的匿名化处理。具体来说,移除了所有能够直接识别用户身份的信息,并对可能间接透露用户身份的敏感数据进行了脱敏处理,确保了用户隐私的安全。表2详细列出了该数据集中的用户数、多样化的兴趣标签以及标签的总数。其中,用户兴趣标签的分布展现出了显著的广泛性,每一类标签都根据统计的百分比进行表示,如图2所示。社交网络平台的数据集为进一步深入剖析并理解用户兴趣进而进行有效的推荐提供了坚实的基础。
2.2 数据预处理
为了提高数据质量,并确保分析结果的精确性和可信度,我们实施了一系列的数据预处理步骤,具体流程如图3所示。
1)数据清洗。数据清洗是数据预处理的重要步骤,目的是去除噪声数据、处理缺失值和解决数据不一致性。例如,在提供的数据集中有些用户的兴趣标签可能存在缺失,或者标签数据包含错误信息,因此需要对数据集进一步处理。首先计算清洗后的数据比例。假设原始数据量为D,清洗后的数据量为D',则有:
3)数据划分。在社交网络数据集中,数据的划分对于后续的分析至关重要。随机打乱数据和按比例划分数据是两种常见的数据划分方式。
随机打乱数据可以确保数据集的随机性和均匀性,避免数据集的顺序或结构特性而导致的算法偏差。这有助于算法更公平、更全面地探索数据集中的关联规则。
按比例划分数据可以确保在数据分布上保持一致,能够更准确地评估算法的性能和挖掘出的关联规则的有效性。
在Apriori算法中,这两种数据划分方式可以根据具体的应用场景和需求灵活选择或结合使用,以达到最佳的数据挖掘效果。
3 Apriori 算法改进
在处理大规模数据集时,传统的Apriori算法暴露出一些固有的缺陷,核心问题包括:一是会产生大量的候选项集,这增加了算法的复杂度;二是必须多次扫描整个数据集,导致时间和计算资源的显著消耗。这些挑战阻碍了算法在大数据场景下的有效应用。为了应对这些挑战并提升算法效能,本研究对经典Apriori算法进行了优化,旨在提高其运算效率和扩大其应用范围。
3.1 动态调整支持度阈值
传统的Apriori算法使用固定的支持度阈值来筛选频繁项集,这可能导致一些重要的,但出现频率稍低的项集被忽略。在本研究的改进中,引入了动态调整支持度阈值的机制。通过分析用户兴趣标签的频率分布,算法能够动态地调整支持度阈值。这种动态调整确保了能够挖掘出更具代表性和价值的频繁项集,即使在它们出现的频率略低于传统的固定阈值时也是如此。算法步骤如下:
1)数据预处理
①收集用户的兴趣标签数据,并进行清洗和整理,确保数据的准确性和一致性。
②统计每个兴趣标签的出现频率f (i),为后续动态调整支持度阈值提供依据。
2)初始支持度阈值设定
设定一个初始的支持度阈值min_support。根据用户兴趣标签的总体分布情况来设定,设定为所有标签出现频率的平均值。
3)动态调整支持度阈值
对于每个兴趣标签i,可根据其出现频率f (i)与所有标签出现频率的平均值的比值来调整其支持度阈值。设调整后的支持度阈值为adjusted_support(i)。
其中,average_frequency表示所有兴趣标签出现频率的平均值,α 是一个调整因子,用于控制频率对支持度阈值的影响程度。当α 较大时,频率对支持度阈值的影响更为显著;当α 较小时,频率对支持度阈值的影响较为平缓。
4)Apriori算法应用
使用调整后的支持度阈值adjusted_support(i) 来应用Apriori算法挖掘频繁项集和关联规则。
3.2 并行计算
为了显著提升候选项集的生成速度以及频繁项集的筛选效率,设计一种基于多线程技术的并行计算方案。此方案通过精心策划地将数据集分割成若干个子集,并将这些子集分配给多个线程以并行方式进行处理,从而充分利用了现代多核处理器的计算能力。具体步骤如下:
1)数据集分割
①初始阶段,对整个数据集D进行全面分析,依据数据规模、分布特性及计算资源可用性,将其智能地划分为n个子集,记作D1,D2,...,Dn。
②每个子集Di 均包含一部分原始数据,确保数据划分既均衡又高效,旨在最大化并行计算的性能增益。
2)线程分配与任务调度
将划分后的子集分配给不同的线程,每个线程负责处理一个或多个子集。实现一个有效的任务调度机制,确保所有线程能够协同工作,避免资源竞争和死锁情况,同时最大化计算资源的利用率。
3)并行生成候选项集
①每个线程独立地在其负责的子集上执行Apriori算法的第一步,即生成候选项集。
②通过局部计算,每个线程都能产生一部分候选项集,这些候选项集是基于其分配到的数据子集而得出的。
4)合并与筛选频繁项集
所有线程生成的候选项集会被汇总到一个中央数据结构中,通常是一个共享的内存区域或分布式存储系统。在合并阶段,可能会涉及去重操作,以确保候选项集的唯一性。随后,对所有候选项集进行全局支持度计数,根据动态调整后的支持度阈值筛选出频繁项集。
5)性能优化与负载均衡
①监控各线程的执行情况,动态调整数据集划分和线程分配策略,以实现负载均衡
②利用缓存技术减少内存访问延迟,提高数据访问效率。
③优化线程间通信和数据传输机制,减少不必要的开销。
6)结果整合与输出
最终,所有线程处理完毕后,将挖掘出的频繁项集进行整合,并按照一定格式输出给用户或存储到数据库中。
通过采用上述并行计算方案,算法在候选项集生成和频繁项集筛选方面实现了显著的加速效果。多线程技术的引入不仅提高了算法的执行效率,还增强了其对大规模数据集的处理能力,使得算法在实际应用中更加实用和高效。算法流程如下:输入:数据集D,初始支持度阈值比例min_sup_ratio,调整因子α,并行处理的线程数num_threads。