基于预训练模型的SST-5数据集的五类情感分析
作者: 扎西永珍 拥措
摘要:该文探讨了Robust Sentiment Analysis(RSA) 模型在细粒度情感分类中的有效性,使用SST-5数据集进行实验。本研究利用预训练模型的logits输出作为句子特征向量,随后通过支持向量机(SVM) 和多层感知机(MLP) 进行二次训练。在实验中,对数据进行了详细的预处理,并对特征提取、模型训练和参数调优进行了系统性探索。同时,比较了支持向量机(SVM) 和多层感知机(MLP) 在情感识别任务中的表现。实验结果表明,RSA模型提取的特征具有较强的判别能力,经过SVM和MLP的训练后,分类性能显著提高。研究验证了预训练语言模型在细粒度情感分析中的应用价值,并为社交媒体舆情监测等实际场景提供了有益的实践指导。此外,文章还讨论了模型在误差、噪声处理及局限性方面的挑战,并提出了未来优化的方向。
关键词:情感分析;SST-5数据集;预训练语言模型;微调技术;自然语言处理
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2025)09-0038-04 开放科学(资源服务) 标识码(OSID) :
0 引言
首先,本文的基本概念有:1) 预训练模型是指在大规模数据集上进行训练,以学习通用的知识和特征的机器学习模型。通过在大量的无标签或有标签的数据上预先进行训练,模型能够捕捉到语言、图像或其他任务领域中的普遍规律和模式。预训练模型通常在完成基础训练后,会针对特定任务进行微调,以适应特定应用场景。2) 情感分析是一个用于情感分析的标准数据集,它由斯坦福大学开发,主要用于评估情感分类模型的性能。SST-5数据集是基于电影评论的文本数据,包含五种情感类别:非常负面(verynegative) 、负面(negative) 、中性(neutral) 、正面(posi⁃tive) 和非常正面(very positive) 。这个数据集的特点是每个句子都有人工标注的情感标签,能够帮助研究者训练和评估情感分析模型。3) 自然语言处理是计算机科学和人工智能的一个重要领域,旨在使计算机能够理解、解释、生成和与人类语言进行交互。它涉及计算机与人类语言之间的桥梁,其目标是让计算机能够像人类一样理解和使用自然语言。
近年来,深度学习技术的飞速发展显著推动了自然语言处理(NLP) 领域在文本分类、机器翻译和情感分析等多个任务中的进步。情感分析是NLP的重要分支,核心任务是从文本中提取和判别隐含的情感信息。这对于理解用户情绪、产品评价以及网络舆情监控具有重要意义。传统情感分类方法主要依赖于人工设计的特征或基于词典规则的情感词表,这些方法在面对复杂语义表达及多样化语言现象时常显不足[1-2]。与此同时,近年来兴起的预训练语言模型(例如 BERT、DistilBERT 等) 通过大规模无监督预训练学习到丰富的语义知识,展现出了强大的上下文语义捕捉能力[3]。尤其值得注意的是,Robust Sentiment Analysis(RSA) 模型通过利用合成数据进行训练,成功地解决了标注数据稀缺的问题,同时在应对各种语言变体、语法错误以及噪声干扰时表现出较高的鲁棒性[4]。这种在多样化应用场景下均能保持较高准确率的模型,为情感分类任务提供了全新的方法论和实现路径。因此,探讨如何充分利用该模型提取的深层语义特征,并结合传统机器学习方法进行情感分类,不仅具有理论创新意义,更具备广泛的实际应用前景,能够为复杂情感信息的准确识别和高效处理提供技术支撑。
1 相关研究
1.1 研究现状
当前情感分析领域的研究主要分为基于传统机器学习方法和基于深度神经网络方法两大类。传统方法(如支持向量机 SVM 和朴素贝叶斯) 主要依赖低维人工设计特征,这类方法在一定程度上能实现情感极性的划分,但由于无法充分捕捉文本中潜在的上下文信息,其性能在处理复杂语义和细粒度情感分类任务时受到较大限制[5]。另一方面,深度神经网络方法,特别是基于预训练语言模型的方法,利用 Transformer 等先进架构实现了多层次的语义表示,显著提升了情感识别的准确性[6]。然而,单纯依赖深层神经网络在面对小样本或特定领域数据时,可能会因过拟合等问题而影响模型的泛化能力。近年来,一种兼具传统机器学习和深度学习优点的混合方法逐渐受到研究者关注:先利用预训练模型提取深层语义特征,再通过传统分类器(如 SVM、MLP) 对提取的特征进行二次训练。相关文献表明,基于 BERT 提取的向量特征不仅能显著提高分类精度,还能在样本数据较少的情况下展现出良好的鲁棒性和泛化能力[7]。因此,如何在当前混合方法基础上进一步优化模型结构、参数调优以及数据预处理策略,以提升情感分类任务的整体性能,成为学术界和工业界亟待解决的关键问题之一[8]。本文所提出的基于 RSA 模型的特征提取与二次训练方法,正是在这一研究背景下应运而生,并有望为细粒度情感分类任务提供全新的解决方案。
1.2 研究目的
本论文实验的主要目标是探讨并验证利用 RSA 模型作为特征提取器,在细粒度情感分类任务中的应用效果。为实现这一目标,我们采用了 RSA 模型的分类头 logits 输出作为句子的特征向量,通过该特征向量来捕捉文本中的深层语义信息。在此基础上,我们构建了两种传统机器学习分类器——支持向量机(SVM) 和多层感知机(MLP) ,对 SST-5数据集进行情感分类任务的二次训练与评估。通过比较两种后续分类器在利用 RSA 模型提取的深层特征进行情感判断时的表现,我们希望揭示预训练语言模型在细粒度情感识别任务中所蕴含的语义信息优势与局限性。具体而言,我们将分析两种传统机器学习算法在处理情感分类任务时的准确率、鲁棒性和训练效率,以便深入理解深层语义特征如何影响情感判断的效果。通过系统性的实验设计和数据分析,本研究不仅期望验证所提出方法的有效性,同时也为复杂情感信息处理问题提供新的解决思路。最终,我们希望本研究能够推动情感分析技术的进一步发展,为实际应用场景中的情感信息处理提供更为精准和高效的技术支持,并拓展该领域的应用范围。
2 情感分析实验
2.1 实验技术方案
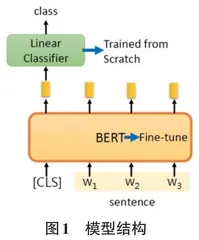
本实验旨在通过结合预训练的 RSA 模型与传统算法提高情感分类性能。本研究采用基于DistilBERT-base-uncased 架构的预训练模型 RSA。该模型通过知识蒸馏技术有效压缩了原始 BERT 模型的参数量,在保持高性能的同时,显著提高了推理效率。模型结构如图 1 所示。
本实验采用两阶段混合方法,将预训练的 RSA 模型与传统机器学习算法相结合,以提高情感分类性能,旨在提升细粒度情感分类任务的表现。实验的第一阶段,利用预训练的 RSA 模型提取文本的深层语义特征。RSA 模型的核心思想是使用模型分类头输出的 logits 作为句子的向量表示。具体来说,本实验采用 DistilBERT-base-uncased 架构,这是一种通过大规模无监督预训练的深度学习模型,能够捕捉文本中的丰富上下文信息。由于 DistilBERT 是基于 BERT 模型的轻量化版本,它不仅保留了 BERT 的高效语义理解能力,还在计算上更加高效且具备较高的鲁棒性,能够处理复杂的情感分析任务。
在特征提取阶段完成后,实验进入第二阶段,使用两种传统机器学习算法进行二次训练:支持向量机(SVM) 和多层感知机(MLP) 。首先,SVM 采用 hinge 损失函数,通过最大化类别间的间隔,实现对高维特征的有效线性划分。为了获得最佳性能,使用网格搜索来确定SVM模型的超参数配置,包括 C 值和核函数等。其次,MLP 采用一个简单的神经网络架构,包含一层隐藏层(64 个节点) 和一层批归一化层。使用交叉熵损失函数,通过反向传播优化网络权重,并结合 AdamW优化器进行优化。为了进一步提升训练效果,还采用了余弦退火策略来调整学习率。
整个实验流程由这两个阶段构成:首先从RSA模型提取深层特征,然后利用 SVM 和 MLP 两种传统算法进行分类训练,以期达到更好的分类效果。该方法能够有效融合深度学习和传统机器学习的优势,在情感分类任务中取得较好的性能。
2.2 训练
训练损失函数:SVM部分采用 hinge 损失函数,通过最大化类别间的间隔实现高维特征的线性划分;MLP部分同样采用交叉熵损失函数,通过反向传播不断调整网络权重,优化模型的分类性能。
实验训练过程分为以下几个主要步骤,1) 模型加载:首先调用 Hugging Face Transformers 库加载预训练的RSA 模型,并初始化相应的 tokenizer 与配置参数;2) 特征提取:将预处理后的训练文本输入模型,记录分类头输出的 logits 特征,并保存为特征矩阵;3)SVM 训练:利用 scikit-learn 库实现 SVM 分类器,在验证集上进行超参数网格搜索;4) MLP 训练:设计包含一层隐藏层以及一层批归一化层的神经网络结构,采用 AdamW 优化器和适当的学习率进行训练,同时记录每个 epoch 的损失变化,使用余弦退火学习率算法调整学习率;5) 模型保存:在模型训练结束后,将SVM 与 MLP 模型分别保存,以便后续在测试集上进行评估。
损失函数变化曲线图如图2 所示。
2.3 实验与分析
1) 超参数和训练:在SVM部分,通过网格搜索确定最佳参数配置为:C=1.0,核函数采用 RBF;而MLP 部分采用一层隐藏节点为 64 的隐藏层和一层批归一化层,激活函数为ReLU,学习率设为 0.001,训练ep⁃och数设为 20。
2) 实验结果:表1列出了在 SST-5 数据集上各方法的测试结果,包括准确率、精度、召回率和F1分数,采用不同方法进行情感分类实验的性能对比结果。整体来看,直接使用 RSA 模型提取的深层特征进行分类所获得的各项指标均低于采用二次训练方法的结果。RSA 模型:单独使用预训练模型的logits作为特征,其准确率仅为 36.88%,精度和召回率分别为42.14% 和38.81%,F1 分数为 37.55%。这些结果表明,仅依赖 RSA 模型的特征提取在细粒度情感分类任务中效果有限。RSA+SVM 方法:结合 SVM 进行二次训练后,各项指标均有明显提升。准确率提高到46.47%,精度达到48.59%,召回率和 F1 分数分别为40.91% 和 40.32%。这说明 SVM 在利用深层特征进行线性划分时,能够更有效地区分情感类别。RSA+MLP方法:采用 MLP 进行二次训练的结果显示,准确率达到了 47.29%,精度为 48.34%,召回率和 F1 分数分别上升到 43.13% 和 43.22%。相较于 RSA+SVM,MLP 在召回和 F1 分数上有更进一步的提升,表明其在捕捉复杂特征关系上具有一定优势。
2.4 与其他基线模型的比较
图3 展示了本文方法与其他基线模型(Emo2Vec[9],GloVe+Emo2Vec[9],MV-RNN[10],Joined Model[11],GRU-RNN[12]) 在 SST-5 数据集上的对比情况,可以直观地看出本文方法在准确率等指标上具备一定优势。
2.5 消融实验
表2 列出了在 SST-5 数据集上各方法的测试结果,使用停用词,包括准确率、精度、召回率和 F1 分数。在消融实验中,笔者通过对比在移除停用词(来自 NLTK) 与保留停用词两种预处理策略下模型的表现,进一步探讨了停用词对情感分类模型性能的影响。实验结果如表 1 所示(未去除停用词) ,同时对比了不同预处理策略下的模型效果。
在实验中,保留停用词的策略普遍带来了性能上的提升,尤其是在一些细粒度情感分类任务中,保留停用词能够更好地帮助模型捕捉文本中的细微语义信息。具体来看,在单独使用 RSA 模型的情况下,保留停用词时模型的准确率为 36.88%,而移除停用词后的准确率仅为 33.44%,差距明显。这一结果表明,停用词的存在可能在情感表达中起到了潜在的作用,尤其是对某些情感表达的准确捕捉。
进一步分析,结合 SVM 的 RSA 模型在保留停用词情况下准确率达到了 46.47%,相比移除停用词时的 42.67%,提升了约 3.8 个百分点,这一差距进一步证明了停用词的有效性。类似地,在 RSA+MLP 方法中,保留停用词时准确率为 47.29%,远高于去除停用词后的 43.36%。
这些数据表明,停用词(例如,否定词、程度副词等) 在情感分类任务中可能发挥了关键作用。停用词往往能够帮助模型更好地理解句子的情感倾向,尤其是在复杂句式和细微情感变化的情况下,停用词的作用不容忽视。移除停用词虽然可以减少噪声,但可能也忽略了一些对情感判别有价值的语义信息。因此,保留停用词有助于模型更全面地捕捉语义信息,提升情感分类的性能,特别是在细粒度情感分析任务中。
3 结论
本研究基于 RSA 模型,探讨了细粒度情感分类的有效方法。具体而言,首先提取了 RSA 模型分类头输出的 logits 作为句子特征向量,这些深层特征能够更好地捕捉文本中的细微情感信息。接着,结合传统的机器学习方法,使用支持向量机(SVM) 和多层感知机(MLP) 对提取的特征进行二次训练,进一步提升了情感分类的性能。实验对象为 SST-5 数据集,该数据集包含多类别情感标签,是情感分类任务中的经典数据集。
实验结果表明,RSA模型在挖掘深层语义特征的过程中表现出了较强的判别能力,在SVM和MLP两种分类器的训练下,分类性能得到了显著提升。此外,论文还对数据预处理、特征提取、模型训练以及参数调优等多个环节进行了详细探讨。这些细致的探索不仅有助于提升模型的性能,也为后续的情感分析研究提供了有益的思路和实践参考。
通过实验,本文验证了深度学习模型与传统机器学习方法结合的潜力,并为情感分析在社交媒体舆情监测、客户反馈分析等实际应用场景中提供了理论依据和应用指导。研究还对模型可能存在的误差、噪声以及局限性进行了深入分析,并提出了未来优化的方向,为情感分析技术的发展开辟了新的研究路径。