基于近红外激光拉曼光谱的山茶油掺假判别分析方法研究
作者: 张倩 许晖 柯振华 陈萱萱
摘 要:采用1 030 nm激发光源的近红外拉曼光谱结合数据驱动型簇类独立软模式分类法、偏最小二乘法对山茶油与几种食用油进行聚类分析和掺假定量分析。结合数据驱动型簇类独立软模式分类法的一类判别分析发现建立的鉴定模型能将山茶油和大豆油、玉米油、花生油、葵花籽油样本分开,校正集和预测集的灵敏度和特异性均达到100%;结合偏最小二乘法能准确进行山茶油掺假定量分析,结果准确可靠,最低检测限可达5%,为山茶油鉴定与掺杂量预测提供了一种快速、简单、准确的方法。
关键词:山茶油掺假;近红外拉曼光谱;偏最小二乘法;数据驱动型簇类独立软模式分类法(DD-SIMICA)
Abstract: Near-infrared Raman spectroscopy on 1 030 nm excitation light source combining with data driven soft independent modelling of class analogy method and partial least-square method were used to cluster analysis and adulteration quantity of Camellia japonica L. oil and other edible oil. The one-class discriminant analysis combining with data driven soft independent modelling of class analogy method was established could distinguish Camellia japonica L. oil and soybean oil, corn oil, sunflower seed oil sample, the sensitivity and specificity of calibration set and predictive set both reached 100%. Partial least-square method was combined to adulteration quantitative analysis of Camellia japonica L. oil, the results were accurate and minimum detection limit reached 5%. The methods were speedy, simple and accurate to identification and adulteration quantitative prediction of Camellia japonica L. oil.
山茶油是我国特有的木本油脂,在国际、国内市场上备受消费者青睐。山茶油营养价值高,碘值含量低,富含不饱和脂肪酸以及维生素E、角鲨烯等抗氧化成分,不含棉酚、芥酸和皂素等有害物质,在高端植物油市场中占有较高的比例[1-2]。山茶树从种植到开花结果需要6~10年,且山茶籽多采用机械方式压榨,生产加工工艺复杂,产油率低,所以山茶油的价格比其他食用油高3~5倍[3]。然而市场上各种山茶油品质良莠不齐,将廉价油掺入山茶油中的侵权事件时有发生,因此对山茶油掺假进行判别尤为重要。开展快速准确的食用油掺假判别检测是食品安全监控领域的一项技术性难题。实验室通常采用色谱法检测食用油中的脂肪酸、甾醇、甘油三酯、碳水化合物和挥发性物质等成分,再与国家标准中不同植物油的脂肪酸组成成分和含量进行比较,判别食用油的种类和品质[4-5]。而各类植物油的40余种脂肪酸组成成分类似、含量不同,仅用检测油品中脂肪酸组成和含量的方法来鉴别掺假情况工作量大,而且较难实现快速定性、定量掺假判别。
拉曼光谱法是一种以物质特定的分子振动光谱来识别不同结构的无损检测技术,并对C=C、C≡C和C≡N等基团存在较敏感的特征信号,成为分析食用油掺假的有力工具[6]。近红外拉曼的激光源波长范围通常在780~2 526 nm,几乎所有食用油脂肪分子的主要结构和组成都可以在拉曼光谱中找到信号,且谱图稳定[7]。由于近红外拉曼光谱产生的能量低于激发荧光所需阈值,可以避免大部分荧光的干扰,同时激发光波长越长,穿透深度越深,因此近红外光的拉曼信号比可见光的拉曼信号能够提供更多的信息,可以快速、简便地对多组分样品尤其是食用油样品进行光谱分析[8]。
由于不同植物油之间的光谱差异较小,通常需要结合主成分分析(Principal Component Analysis,PCA)、偏最小二乘法(Partial Least Square Method,PLS)、线性判别分析法(Linear Discriminant Analysis,LDA)、K最近邻分类算法(K-Nearest Neighbor Algorithm,KNN)等化学计量法对光谱数据进行聚类判别分析[9-10]。本研究采用1 030 nm激发光源的近红外拉曼光谱结合数据驱动型簇类独立软模式分类法(Data Driven Soft Independent Modelling of Class Analogy Method,DD-SIMCA)、PLS等数据分析方法对山茶油与几种食用油进行聚类和掺假定量分析,实现对山茶油掺假鉴别的定性、定量高效识别,为食用油掺假的监管检测领域提供有效的技术支撑。
1 材料与方法
1.1 试验样本
聚类分析的实验样本为厂家提供或市场购买的5种食用油共99个样本(17份山茶油、22份玉米油、40份花生油、12份葵花籽油和8份大豆油)。掺假定量分析的样本为选取2个厂家提供的山茶油样本分别掺入不同比例(5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%和95%)的大豆油、葵花籽油、玉米油以及1∶1的玉米大豆油,共计152个样本;掺入不同比例(5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%和60%)花生油,共计24个样本;掺入不同比例(5%、10%、15%、20%、25%、30%、35%、40%、45%和50%)棕榈油,共计20个样本,再加8个未掺杂样本合计204个植物油样本。
1.2 拉曼光谱采集
①仪器条件:Inspector 500拉曼光谱仪激光器为Class III B 1 030 nm,激光输出功率300 mW;CCD为TE制冷Ⅲ-Ⅳ半导体阵列;光谱分辨率为8~10 cm-1。②拉曼光谱采集:分别从1 mL带盖石英进样瓶中移取800 μL食用植物油样本,置于样品池中采集拉曼光谱,在2 h内完成测试。光谱积分时间为15 s,平均次数为5次。
1.3 光谱数据处理及建模
选择光谱范围为150~2 450 cm-1,所有的光谱数据都去除荧光背景、平滑以及归一化处理后,采用MATLAB R2018a软件来进行数据处理及建模。DD-SIMCA是基于主成分分析,用于将某个特定目标类别从其他所有对象类别中区分出来的一种模式识别方法[11]。偏最小二乘法主要是研究多个自变量与因变量之间的相关关系,是基于因子分析的多变量校正方法,通常被用于特征提取和聚类分析、线性模型拟合以及定量校正模型适用性判断等[12]。
2 结果与分析
2.1 植物油样品的拉曼光谱分析
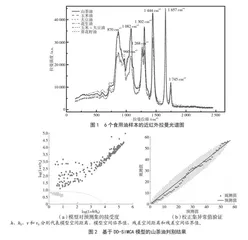
5种食用油(山茶油、花生油、大豆油、玉米油和葵花籽油)以及大豆油和玉米油(1∶1)的近红外拉曼光谱如图1所示。6种植物油,特别是山茶油和花生油的拉曼光谱图和特征峰位置类似,拉曼特征峰都集中在800~1 800 cm-1,但峰值强度存在差异,这也为使用拉曼光谱法鉴别不同植物油以及掺假情况提供了理论基础。食用油的拉曼特征谱峰反映了分子振动方式和对应的官能团信息,图1中拉曼频移在870 cm-1、1 302 cm-1和1 444 cm-1处的特征谱峰分别对应-CH2的伸缩振动、卷曲振动和剪式振动;960 cm-1和1 657 cm-1分别表示C=C的弯曲振动峰以及顺式C=C的伸缩振动峰;1 082 cm-1和1 268 cm-1主要对应脂肪酸分子中的C-C弯曲振动;1 745 cm-1是羰基的C=O伸缩振动峰[13]。
2.2 基于DD-SIMCA的一类判别分析
本文随机选取5种植物油中的67个食用油样本作为训练集,剩下的32个食用样本作为预测集,使用DD-SIMCA算法等进行山茶油与其他种类植物油的一类判别分析。将随机选取的校正集和预测集样本均按照山茶油和其他油分为两类,设定计算参数为校正集数据采用中心化预处理,主成分数为3,接受区域类型选择卡方分布,并使用经典的估值方法(α=0.01;γ=0.01)[14]。
为了测试模型对目标类(山茶油)新数据集的接受和拒绝能力,分别用预测集中山茶油、非山茶油和所有类别样本数据进行验证[15],结果见图2(a)。图2(b)显示所有的校正集数据都在公差范围内(以垂直线表示),表明基于DD-SIMCA模型的校正集不包含异常值。因此该5种食用植物油样本的近红外拉曼光谱与DD-SIMCA结合建立的鉴定模型能将山茶油和其他类别样本分开,此方法的灵敏度和特异性均达到100%,能有效识别山茶油和其他类别食用油。
2.3 基于偏最小二乘法的山茶油掺假定量分析
本文采集了8个纯植物油样本和196个掺杂样本的近红外拉曼光谱,将数据集分别按3∶1随机分为校正集和预测集,通过偏最小二乘法将不同掺杂量的植物油光谱进行建模分析。山茶油掺假的真实值和预测值相关图如图3所示,该方法对于对掺杂了不同种类、不同比例的山茶油样本可以进行有效的定量分析。
基于PLS的山茶油掺假定量分析结果评价如表1所示,山茶油掺杂其他种类植物油的校正均方根误差(Root Mean Squared Error of Calibration,RMSEC)为0.501 2~3.052 7,预测均方根误差(Root Mean Squared Error of Prediction,RMSEP)为1.455 0~4.712 9,R2为0.988 8~0.998 9,尤其是掺杂花生油、棕榈油和掺杂玉米大豆油的模型建立得较好。因此利用近红外拉曼光谱建立的PLS模型进行山茶油定量掺假判别准确可靠,能满足山茶油中掺杂其他种类植物油的定量判别要求,最低检测限可达5%。
3 结论
本文对不同种类的植物油以及掺假山茶油的近红外拉曼光谱进行分析,发现山茶油与大豆油、玉米油、花生油和葵花籽油5种食用油样本的拉曼光谱与DD-SIMCA结合建立的鉴定模型能将山茶油和其他类别食用油样本分开,方法的灵敏度和特异性均达到100%。同时近红外拉曼光谱结合PLS的方法能准确进行山茶油掺假定量分析,结果准确可靠,最低检测限可达5%,为山茶油品质鉴定与掺杂量预测提供了一种快速、简单、准确的方法,在实际应用中具有一定的参考价值。因此采用近红外激光拉曼光谱结合化学计量学方法可以实现对山茶油掺假的定性定量高效判别。
参考文献
[1]刘燕德,谢庆华.山茶油品质检测方法现状研究[J].食品工业,2016,37(6):253-257.
[2]SHI T,WU G,JIN Q,et al.Camellia oil adulteration detection using fatty acid ratios and tocopherol compositions with chemometrics[J].Food Control,2022,133:108565.
[3]钟小荣.山茶油营养价值和发展研究[J].中国食品工业,2021(22):72-75.
[4]冯棋琴,马玉琼,吴满梅,等.不同产地压榨山茶油挥发性风味成分顶空取样GC-MS分析[J].中国油脂,2018,43(2):138-141.
[5]CHECHETA O V,SAFONOVA E F,SLIVKIN A I,et al.Evaluation of the purity of vitamin a oil-based preparations by thin-layer chromatography[J].Pharmaceutical Chemistry Journal,2008,42(12):721-723.