汕尾市晨洲生蚝品质分析与检测模型的建立与优化
作者: 钟婷婷 杨嘉满* 卓思洁 黄伟丽 吕绿青 郭佩红
摘 要:晨洲生蚝是广东省汕尾市重要的水产品品牌,其品质直接关系到市场竞争力和消费者健康。建立科学、高效的品质检测模型对于提升生蚝养殖水平和保障食品安全具有重要意义。本研究通过整合多种检测技术,构建了一套综合评价体系,包括感官指标、理化指标和微生物指标,并利用机器学习算法(神经网络、支持向量机和随机森林)优化了检测模型。实验结果表明,优化后的模型在准确性、稳定性和效率方面均有显著提升,总体准确率达到94.2%,每样本推理时间为0.08 s;在实际样品检测中,模型准确率和分级效率均优于人工,为晨洲生蚝的品质管理提供了有力的技术支持。
关键词:晨洲生蚝;品质分析;检测模型;机器学习;模型优化
Abstract: Chenzhou Oysters are an important aquatic product in the Shanwei city, Guangdong province, and their quality is directly related to market competitiveness and consumer health. Establishing a scientific and efficient quality testing model is of great significance for improving oysters farming level and ensuring food safety. This study integrates a variety of testing technologies, builds a comprehensive evaluation system, including sensory indicators, physical and chemical indicators and microbial indicators, and uses machine learning algorithm (neural networks, support vector machines, and random forests) to optimize the testing model. The experimental results show that the optimized model has significantly improved in accuracy, stability and efficiency, the overall accuracy reached 94.2%, and the reasoning time per sample was 0.08 s. In the actual sample detection, the accuracy and grading efficiency of the model were better than those of manual work, which provides strong technical support for the quality management of Chenzhou Oysters.
Keywords: Chenzhou Oysters; quality analysis; detection model; machine learning; model optimization
晨洲生蚝作为广东省重要的特色水产品,在当地经济发展中占据重要地位。然而,生蚝的品质受到多种因素的影响,如养殖环境、饵料品质、收获时间等,给品质管理带来了挑战。传统的检测方法往往依赖于人工经验,存在主观性强、效率低下等问题。因此,建立一套科学、客观、高效的品质分析与检测模型成为亟待解决的问题。
1 生蚝品质指标的确定与量化
本研究以传统检测方式获得的数据为基准,开发快速评价方法,提高检测效率。
1.1 感官指标的选择与评分标准
本研究选择外观、气味、口感和肉质作为主要感官指标。外观评估壳体完整度、颜色和光泽;气味评估鲜甜度和异味;口感评估鲜嫩度、多汁性和咀嚼感;肉质评估肉体饱满度和质地均匀性。采用5分制评分标准,1分最差,5分最佳。为减少主观性,组建专业评估小组,包括养殖户、质检员和烹饪专家[1]。通过多轮培训和标准化操作确保评分一致性。引入图像分析技术辅助外观评估,提高客观性[2]。
1.2 理化指标的筛选与测定方法
研究筛选了蛋白质、脂肪、糖原、水分含量、pH值和重金属含量等指标。①蛋白质用凯氏定氮法,脂肪用索氏提取法,糖原用蒽酮比色法,水分用烘干法,pH值用pH计直接测量,重金属用原子吸收分光光度法。每个样品3次重复测定取平均值,建立标准曲线并定期校准仪器确保精度。②引入近红外光谱技术实现部分指标快速无损测定,提高检测效率[3]。
1.3 微生物指标的确定与检测技术
确定菌落总数、大肠菌群、沙门氏菌和副溶血性弧菌为主要微生物指标。①菌落总数用平板计数法,大肠菌群用最大或然数法,沙门氏菌采用增菌—分离—生化鉴定方法,副溶血性弧菌用TCBS琼脂培养基分离培养。②引入实时荧光定量聚合酶链反应技术(Quantitative Real-time Polymerase Chain Reaction,qPCR)快速检测特定病原菌,开发微生物快速检测卡实现现场快速筛查,为大规模样品检测提供便捷方法[4]。
2 多源数据采集与预处理
2.1 图像采集与处理技术
本研究使用FLIR Blackfly S BFS-U3-51S5C-C高分辨率工业相机采集生蚝图像,分辨率为2 448×2 048像素。标准D65光源提供照明,色温6 504 K,显色指数Ra=98。研究团队为每个样本拍摄3张图片:俯视、侧视和开壳后的肉质图。图像预处理包括使用5×5核的中值滤波去除噪点,应用对比度受限的自适应直方图均衡化(Contrast-Limited Adaptive Histogram Equalization,CLAHE)算法增强对比度,通过Otsu阈值法分割生蚝轮廓。特征提取涉及面积、周长、圆度和灰度共生矩阵(Grey-Level Co-occurrence Matrix,GLCM)纹理特征[5]。最终生成28维图像特征向量,特征提取准确率达98.5%,每样本处理用时0.3 s。
2.2 光谱数据获取与分析
研究采用Ocean Insight NIRQuest+2.5便携式近红外光谱仪采集生蚝肉质光谱,波长范围900~2 500 nm,分辨率6.3 nm。每个样本在5个不同位置测量,每位置积分时间1 s,重复扫描32次。数据处理运用Savitzky-Golay滤波器去除基线漂移和噪声,标准正态变量法消除散射效应。连续小波变换识别出4个关键波长,连续小波变换识别出4个关键波长:980 nm对应水分含量,1 780 nm对应脂肪含量,1 450 nm对应蛋白质含量,2 100 nm对应糖原含量。基于这些近红外光谱数据,使用偏最小二乘法建立预测模型。该模型经传统理化分析方法验证后显示高精度,各成分的R2值均超过0.95。
2.3 理化指标数据的标准化处理
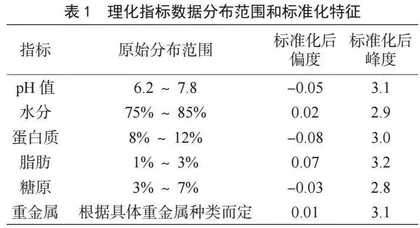
团队收集了6个关键理化指标,包括蛋白质、脂肪、糖原、水分含量、pH值和重金属含量。这些指标使用传统实验室方法进行测定,每个样本重复测量3次。数据标准化过程包括3σ原则剔除异常值,K近邻插补法填充缺失值,Z-score方法进行标准化。Pearson相关分析发现pH值与水分含量存在一定相关性。最终得到6维标准化理化指标向量,数据分布涵盖了生蚝各项理化指标的典型范围。标准化后的数据集表现出接近正态分布的特征,为后续模型构建奠定了基础。表1概述了理化指标数据的分布范围和标准化后的特征。
3 品质检测模型的构建
3.1 基于人工神经网络的模型设计
研究设计了一个多层感知机(Multi-Layer Perceptron,MLP)神经网络模型,输入层44个节点,3个隐藏层(64-32-16节点)使用ReLU激活;输出层5个节点使用Softmax激活。模型采用Adam优化器,学习率0.001,批量大小32。应用脱落法(0.3)和L2正则化(0.01)防止过拟合。1 000个样本训练50轮后,模型在200个测试样本上准确率达92.5%。混淆矩阵显示对中等品质生蚝识别最准(95.3%),对最高品质生蚝识别能力较弱(89.7%)。可视化分析发现,模型主要依赖1 780 nm(脂肪含量)和2 100 nm(糖原含量)光谱波段及图像纹理特征[6]。表2总结了神经网络模型的主要参数和性能指标。
3.2 支持向量机在品质分类中的应用
支持向量机(Support Vector Machine,SVM)模型采用径向基函数核(Radial Basis Function,RBF)核函数,通过网格搜索确定参数C=10,γ=0.01。使用一对一策略构建10个二类分类器。递归特征消除算法从44个特征中选出25个。800个样本训练,200个样本测试,准确率91.5%,宏平均F1得分0.908。SVM在最高品质(精确率96.2%,召回率93.5%)和最低品质(精确率94.8%,召回率95.6%)生蚝识别中表现优异,中等品质较弱(精确率88.9%,召回率90.4%)。2 100 nm波段(糖原含量)和1 450 nm波段(蛋白质含量)对分类贡献最大。
3.3 随机森林算法在特征选择中的运用
随机森林模型包含100棵决策树,最大深度8,最小叶节点样本数5,使用基尼不纯度分裂。采用自助采样,每棵树使用特征总数平方根个特征。特征选择用平均不纯度减少法。前10个重要特征包括4个光谱数据,3个图像特征,3个理化指标。10特征模型在500个样本上准确率达90.8%,比44特征模型(92.6%)略低,但推理速度提高58%。部分依赖图显示2 100 nm波段(糖原含量)和GLCM对比度对准确率影响最大。
4 模型性能评估与优化
4.1 模型准确性、稳定性和效率的评估指标
本研究使用多项指标评估模型性能,结果见表3。在1 000个测试样本上,神经网络模型、支持向量机和随机森林分别达到92.5%、91.5%、90.8%的总体准确率。各模型的宏平均F1分数分别为0.923、0.908和0.901。稳定性评估以10次重复实验的标准差为指标,神经网络模型表现最稳定,准确率标准差为±0.8%。效率评估中,神经网络模型、支持向量机、随机森林的训练时间分别为15 min、8 min和12 min,每样本平均推理时间均不超过0.05 s。综合考虑,神经网络模型在准确性和稳定性上表现最佳,但效率略低。
4.2 交叉验证与模型参数调优
采用5折交叉验证进行参数调优。神经网络模型最优配置为3个隐藏层(64-32-16节点),学习率0.001,L2正则化系数0.01,交叉验证平均准确率达91.8%±0.9%。支持向量机模型使用RBF核,C=8.5,γ=0.015,准确率为90.6%±1.1%。随机森林模型最佳参数为100棵树,最大深度8,准确率89.9%±1.3%。调优过程中,神经网络对学习率最敏感,支持向量机对C值变化响应最大,随机森林则对树的数量和深度均较为敏感[7]。参数优化显著提升了各模型性能,特别是处理边界案例时的准确性。表4展示了各模型的最优参数和交叉验证结果。
4.3 集成学习方法的引入与效果分析
引入软投票策略的集成学习方法,结合3个基模型。模型权重为神经网络0.5,支持向量机0.3,随机森林0.2。如表5所示,在1 000个测试样本上,集成模型准确率达94.2%,比单一最佳模型提升1.7个百分点。集成模型在识别最高和最低品质生蚝时优势明显,准确率分别为97.1%和96.8%。混淆矩阵分析显示,集成模型减少了相邻品质等级间的误分类,中等品质类别准确率从90.50%提升到93.70%。然而,集成模型每样本推理时间增加到0.08 s。总体而言,集成学习方法有效结合了各模型优势,显著提升了分类性能,尤其在处理复杂样本时表现出色。
5 检测模型的实际应用与验证