揭秘数字人,让教师解放出来
作者: 倪俊杰
编者按:近年来,尤其是在生成式人工智能爆火之后,数字人技术如一颗璀璨的星星在科技领域迅速崛起,正以前所未有的影响力改变多个行业的格局。从最初的概念萌芽到如今令人瞩目的发展,数字人技术已经逐渐成为一种重要力量。本期文章将深入揭秘数字人技术的起源、内在原理以及在教育领域的应用,探寻数字人是如何为教师“减负”,释放教师精力,创造更多教育价值,也关注其可能带来的新挑战。下期,我们将关注如何具体实现数字人,为教师所用。
摘要:数字人技术作为科技领域的新兴力量,融合了多种技术实现模拟真人,能在多场景中与人类交互,应用范围广泛。本文阐述了数字人技术原理,并提出,大模型与数字人的结合为教育带来新可能,其能拓展学生学习能力,增强学习交互性,提升知识共创力,为教师“减负”。同时文章也指出,数字人应用也存在安全隐忧,如引发伦理法律问题、数据隐私保护问题等,未来人类与数字人共存将面临新挑战。
关键词:数字人;语音克隆;大模型;教师
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2024)23-0000-05
认识数字人
数字人(又称虚拟数字人,本文统称“数字人”)是一种通过计算机图形学、深度学习等多种技术手段,高精度模拟真人外貌、声音、动作和表情,并且能够在一定程度上实现自主交互和智能反应的虚拟人物。它可以在众多场景中与人类互动,提供多样化的服务或娱乐体验。2023年9月,杭州亚运会开幕式上的“数字人”点火仪式,引发了广大网友的赞叹和好奇。在主火炬点燃前,全球超过1亿位“数字火炬手”组成了一个巨大数字人。这是亚运会史上第一次“数字点火”,也是裸眼3D技术、增强现实和人工智能技术的完美结合。如今,数字人几乎进入了生活的各个角落,在刷视频、听音乐、看新闻的时候,你都可能邂逅数字人的“作品”。据媒体预测,到2025年中国虚拟人市场规模有望达480.6亿元,用户群体主要为中小型企业,需求主要集中在电商、卫生、社会保障和社会福利业、教育、金融和运输业等行业,产品类型以数字员工和定制化数字人为主。
从内涵界定来看,数字人目前并没有一个严格的定义。按照中国人工智能产业发展联盟《2020虚拟数字人白皮书》中的定义,数字人需要满足三点:一是要拥有人的外观;二是要拥有人的行为,如语言、口型、面部表情、肢体动作等;三是要拥有人的思想,如能识别外部环境、与人交互等。按照以上标准,我们常见的一些动画片、电影中的虚拟形象并不能算作数字人,因为它们虽然拥有人的外观和行为,但是不能识别外部环境,更不能与人进行交互。数字人形象是由多项技术综合集合而成的。其中,语音合成技术可以生成数字人的语音,表情生成技术可以生成数字人的表情,动作生成技术可以生成数字人的动作。随着技术的不断发展,数字人将变得更加逼真、自然、智能,越来越像真的“人”。
从实现效果来看,数字人可分为2D和3D两类。2D数字人应用广泛,如新京报贝壳财经的“AI小贝”、虚拟数字人“Ada”等。3D数字人中比较有名的是虚幻引擎的meta human,其背后涉及blendShape(混合形状动画)等先进技术。2024年5月17日,湖南博物院首次公开发布“辛追夫人”3D数字人形象,他们以马王堆汉墓出土的辛追为原型,进行数字形象建立和互动智能体打造,高度还原其容貌,展示了3D数字人的高超技艺。当人工智能技术快速发展之后,数字人作为数字技术的前沿产物,正以前所未有的形态融入我们的日常生活。AIGC技术的发展,使得诸如Midjourney、Sora、腾讯智影等数字人生成的门槛越来越低,也激发了人们对数字人的强烈需求。
从应用范围来看,数字人技术已经在各行各业发挥着重要作用。例如,虚拟主播可以应用于新闻、直播、娱乐等领域;虚拟导购在商场、超市、博物馆等领域随处可见,一些旅游景区或者博物馆之类的地方,也会采用数字讲解员,其服务效果比冷冰冰的语音讲解器更有感染力,让人觉得更亲切;虚拟客服主要应用在银行、电信、运营商等领域,一个具有人类形象的数字客服会让咨询者感觉更为温暖,更愿意沟通交流解决问题;虚拟教师在教育、培训等领域也有很多应用。
数字人技术的基本原理
数字人技术并非新兴事物,其发展历程可追溯至四五十年前。早在20世纪60年代,波音公司就开始试运用数字化的人体模型来研究飞机驾驶舱的人体工程学设计。当时的“波音人”具备人类的外形,能够模仿人类的常见动作,而且还能在人们设置的场景中模拟人的动作,与环境进行交互。那么,如何理解数字人技术的原理?用一个简单公式来说,数字人=形象生成+语音克隆+智能交互。具体而言,包括以下关键技术。
1.形象生成
形象生成是数字人技术的基石。它需要用计算机图形学、计算机视觉、语音合成等技术,构建逼真的图像、动作和声音,以塑造拟人形象。为了创建不同的虚拟形象,数字人可以用真人的2D视频或3D模型,也可借助生成对抗网络(GAN)等方法。GAN是一种用两个神经网络(生成器和判别器)互相对抗,从噪声中生成高质量图像的技术。数字人的人体建模,与人工智能模型不同,专业的人体建模涉及数据采集、特征提取、模型构建、姿态估计等复杂操作。目前,短视频制作多采用2D平面人体,仅仅是一个拍摄的视频。真正的3D人体建模因受制于成本、终端性能和应用场景等因素而应用较少。
数字人形象生成的关键技术有两个:一是面部表情捕捉,即通过高精度摄像头和传感器捕捉人脸的细微表情变化,并将这些数据转化为数字信号。具体方法包括使用各种细节数据和3D面部网格技术,通过深度学习模型生成高度逼真的面部表情。二是动作捕捉,即利用动作捕捉技术记录人类的身体动作,并将这些动作应用到数字人身上,使其表现出自然的肢体语言。两种技术常常结合使用标记点和无标记点捕捉系统,以及机器学习算法,来精确模拟人体运动。
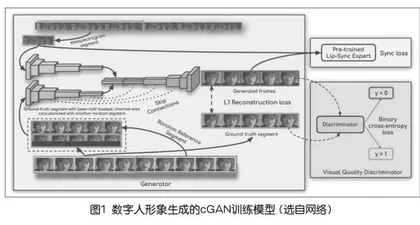
例如,K R Prajwal团队在2020年的ACM国际多媒体会议上发表文章介绍了一款由伦敦帝国理工学院的研究团队开发的人工智能模型——Wav2Lip,主要为了实现音频与视频口型的高度同步。Wav2Lip的出现可以在电影、电视剧、教育视频等制作中,对演员的口型进行精确匹配,提高制作效率和质量,也可以结合数字人模型制作出具有高度自然感的虚拟主播,帮助那些在语言学习中用来生成具有正确口型的发音示例。Wav2Lip的核心是一个条件生成对抗网络(Conditional Generative Adversarial Network,cGAN),通过特征提取——条件生成——对抗训练——循环一致性,生成与条件一致的输出。cGAN的训练一共有一个生成器(下页图1左边大框,Generator)和两个判别器(图1右边两个小框,分别是pre-trained lip-sync expert和visual quality discriminator)。[1]
设置两个判别器是因为设计者认为之前的唇音同步效果不佳,需要一个额外的判别器来判断唇音同步,这种做法使得唇音同步达到91%比例。讲完唇音同步判别器,剩下的一个生成器和一个判别器就跟常规的GAN差不多了。生成器由身份编码器、语音编码器和面部解码器三部分组成,其主要原理是通过一个专家鉴别器来训练,从真实视频学习的唇同步概念来强制生成器实现逼真的唇同步。[1]
2.语音克隆
语音克隆是数字人“说话”的关键技术,基于神经网络的语音合成技术(如Tacotron和WaveNet),将文字转化为自然流畅的语音,其逻辑关系为:声音数据样本→克隆算法→训练模型→模型推理(文本生成语音)。在完成语音克隆后,数字人就拥有了自己的声音模型,我们就可以输入文字,让模型帮你生成一段“模仿”你的语音,这个过程也叫TTS(Text To Speech,文本转语音)。同时,为使数字人讲话更真实,还需要同步口型,使语音与视频中的人物口型匹配。
目前,许多公司的技术只需要通过参考一个小片段的音频,就能够精准复刻语音的情感、重音、节奏和语调,甚至能够跨越不同国家的语言,如MyShell AI开发的开源项目OpenVoice就是其中之一。OpenVoice语音克隆原理主要用到了一个TTS()模型+音色特征提取器(如图2),使用这种编码器+解码器的结构能够控制音频的合成,根据参考音频,最终实现复刻音色。
3.智能交互
智能交互是数字人核心技术之一,赋予数字人“灵魂”和生命力。它深度融合了自然语言处理、语音识别、图像识别及情感分析等尖端技术,实现了全方位、多模态的沟通体验。智能交互是数字人与用户进行沟通和对话的能力,它需要用自然语言处理、语音识别、图像识别、情感分析等技术,实现多模态的交互,包括语音、文字、图像、视频等。以某智能公司的数字人为例,在用户与数字人对话时通过ASR识别用户提出的问题,然后问题被发送给数字人大脑(FAQ+大模型)获取相应的答案,再通过TTS技术将答案转换成音频,经由音频驱动数字人的唇部和面部动作,形成数字人说话视频,从而实现真人与数字人的对话(如图3)。
数字人可以通过构建知识系统(如知识图谱),实现数字人的实时交互和自主学习,但在知识获取、知识融合、知识质量等方面仍面临着诸多挑战。
数字人制作工具
为自己定制数字分身,也成为人们应对多重任务挑战的一种策略:直播带货主播,让数字分身接替了自己的工作;媒体也开发了数字主持人、数字记者等。目前,国内外可选的数字人制作工具也有很多。
1.国外数字人制作工具
国外数字人制作工具发展比较早,且种类丰富。英伟达(NVIDIA)的Omniverse平台通过利用GPU技术和深度学习算法,提供了先进的AI数字人生成工具。该平台能够生成高度逼真的虚拟形象,广泛应用于影视制作、虚拟现实(VR)等领域。Unity Technologies公司推出的虚拟人物生成工具主要面向游戏和影视行业,支持高精度的面部和动作捕捉技术。通过深度学习和机器学习算法,能够生成逼真的虚拟角色,提升用户的沉浸式体验。Epic Games公司创立的Unreal Engine虚拟角色生成工具支持多种面部表情捕捉和语音合成功能,广泛应用于游戏开发、虚拟现实等领域。MetaHuman-Stream作为开源实时交互流式数字人项目,能将数字人类虚拟形象与真实世界无缝融合。通过集成多种AI模型,该技术能够实现高度逼真的声音模拟和流畅的对话交互。用户可以自定义数字人的外观和声音,无论是在线教育还是虚拟客服,都提供了一种新颖、沉浸式的互动体验,推动了虚拟数字人在多样化应用场景中的普及和应用。
2.国内数字人制作工具
近年来,国内数字人技术发展迅猛,涌现出众多优秀的制作工具。阿里巴巴达摩院推出的虚拟形象生成工具,运用深度学习和计算机视觉技术,实现高精度的面部表情捕捉和语音合成,广泛应用于电商直播、虚拟客服等领域,提高了用户的互动体验。腾讯AI Lab的虚拟形象生成工具,支持多语言语音识别和自然语言处理技术。通过深度学习模型生成逼真的虚拟角色,应用于游戏和社交媒体,提升了用户的沉浸感。字节跳动的AI Lab推出了多个虚拟主播和虚拟助手应用。这些工具不仅支持高精度的面部表情捕捉,还具备强大的自然语言处理能力,广泛应用于短视频平台和内容创作。此外,平民化的剪映软件支持公模数据的数字人,也支持上传声音驱动,深受用户喜爱。
大模型+数字人给教师带来无限可能
随着用户需求和产品要求的不断提升,数字人的发展面临着一系列技术挑战。如何在实时交互中生成高质量的虚拟形象,如何提高语音合成的自然度和表达能力,这些都是当前技术亟待解决的问题。而随着大模型的横空出世,数字人领域迎来前所未有的发展机遇。在大模型的加持下,数字人将能够通过自我学习和创造,生成自己的形象、语言、知识和情感,形成自己的个性和风格。