用XEduHub实现零样本图像分类
作者: 谢作如
摘要:用AI解决问题的核心工作是训练模型,而训练模型往往受制于数据的匮乏。因此,借助常见的预训练模型,用零样本训练方式成为一种重要的技术解决方案。本文借助XEduHub中的CLIP模型,使用简洁的代码设计了一个零样本图像分类的实验,为青少年AI科创活动设计提供了一个新思路,并有效简化工作量和复杂度。
关键词:XEduHub;深度学习;零样本图像分类
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2024)23-0000-03
要用AI解决问题,训练一个人工智能模型是核心工作。在带领学生做AI科创活动时,往往受制于数据的匮乏而无能为力。例如,在某教学案例交流活动中,有教师提出想训练一个用于环境保护的模型,对水面的各种漂浮物进行识别,却苦于找不到“死鱼”的数据。即使借助了网络,也因为角度、位置等问题,导致训练出来的模型精度很低。
考虑到XEduHub内置了CLIP模型,又同时具备了文本和图像的特征提取功能,笔者提出了一个假设:能否利用CLIP模型的多模态特征提取能力,来设计“零样本图像分类”的实验,进而解决类似的数据匮乏难题。
零样本图像分类技术简介
零样本图像分类(Zero-shot image classification)是一种图像分类方法,指模型能够对以前未见过的图片类别进行分类。也就是说,零样本图像分类要求模型能够在没有看到特定类别样本的情况下,也能够对这些类别数据进行分类。要实现这一能力,通常需要多模态模型(指同时支持多种类型的数据,如文本、图像、音频等),并且这一模型已经在大量的图像和描述数据集上进行了训练。只需要给模型一些数据相关的额外信息(这被称为辅助信息,可以是描述或属性),模型就能够预测未见过的分类。在一些特定的场景中,如只有少量标记数据,或者想要快速将图像分类功能整合到应用程序中,就很需要用到这种技术。
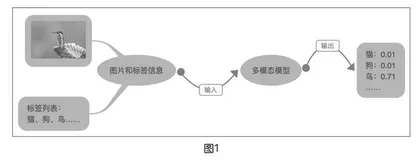
零样本图像分类任务应用很简单,一般会在推理图像时给出可能的标签列表。例如,在推理图像时,同时传递一个标签列表,如飞机、汽车、狗、鸟,模型将会在标签中挑选出可能性最大的标签。如图1所示,即使从来没有训练过“翠鸟”的数据,多模态模型依然能根据描述判断出“鸟”的概率最大。
XEduHub中的CLIP特征向量提取功能
XEduHub中提供了文本特征提取和图像特征提取任务,其实是借助内置的CLIP模型来实现的。CLIP模型(Contrastive Language-Image Pre-training)是基于文本图像对比的预训练模型,也是多模态领域的经典之作,可以同时处理文本和图像。它能将不同模态的原始数据映射到统一或相似的语义空间,实现不同模态信号间的相互理解,基于此实现不同模态数据间的转化与生成。
CLIP模型与以往的图像分类模型不同,它并没有使用大规模的带有标注的图像数据集,而是利用互联网上的未经人工标注的“图像-文本”数据对进行训练。如图2所示,第一张图像是一只小猫,与其配对的文字是“A cute cat”……CLIP模型一共收集了4亿个“图像-文本”的数据对,可见数据集规模相当大。
将图像或者文本输入到XEduHub中,即可得到512维的向量特征。CLIP模型采用的是嵌入(Embedding)技术,意义相近的文本或者图像,得到的向量特征也接近。例如,翠鸟图像和“鸟”这一文本的向量距离(一般使用余弦向量)比和“猫”“狗”会更加接近。按照这样的原理,就能实现零样本图像分类。
零样本图像分类实验的设计
XEduHub内置了CLIP模型,并且在“Workflow”模块中设计了两个任务名称进行调用,分别为“embedding_image”和“embedding_text”。传入一个或者一组图像或者文本,即可输出相应的向量特征。为了方便使用,XEdu提供了几个常用的函数,如get_similarity用于计算相似度矩阵、visualize_probability用于概率分布的可视化。
实验的参考代码如图3所示,其中“image_data/bird.png”为“翠鸟”的图片。对于“cifar10_classes”,笔者选择了常见的图像分类数据集“CIFAR10”的分类信息。
从运行结果(如下页图4)可以看出,CLIP模型准确地识别出“Bird”是概率最大的类别。
零样本图像分类技术的应用与拓展
按照上述实验,只要修改类别标签,就能解决一些常见的分类任务。如果使用更加复杂的分类标签信息,如CIFAR100(100个类别)或者ImageNet(1000个类别),能解决的任务会更多。从原理上看,无非是先提取数据的向量特征,然后在类别标签中找出最接近的。
在CLIP模型发布之后,越来越多的类似模型不断发布。选择一些功能更加强大的多模态模型,还可以解决更多的任务:
①文本分类和知识库。因为大模型容易“胡说八道”,为了确保准确率,目前很多知识库的系统就采用向量特征匹配的方式来实现,如浦育平台中的“文本分类”体验活动,就是采用了阿里达摩院发布的GTE模型来提取向量特征。
②音频分类。一些新发布的多模态模型已经同时支持文本、图像和音频的对应关系。不用做语音识别,也不用训练语音数据,能对常见的语音进行分类。
③图像搜索。先用模型对电脑中的图像进行向量特征提取(可以理解为编码),然后用关键字来搜索图像,是不是很酷?
④景点匹配。看看某段文本对应的是某个景点,当然,这需要在向量数据的基础上继续训练出一个简单的全连接神经网络或者SVM模型。
……
总结
常见的图像分类任务一般都采用监督学习方式,需要准备大量带有标签的图像数据集进行训练。当遇到新的类别时,需要重新训练模型。例如,已经训练了一个猫狗分类器,但是如果又想要区分宠物猪,这个已有的猫狗分类器就不能用了,需要再训练一个包含猫狗和宠物猪的分类器。通过本文中的实验,可以看到零样本图像分类技术将大大简化青少年AI科创活动的工作量。但也要认识到,监督学习方式的图像分类技术依然非常重要。相对来说,使用CLIP模型做图像分类,对边缘硬件的算力要求较高,而且不适合做对精度要求较高的任务。同样,除了多模态模型外,单模态的模型也采用类似方式来解决一些问题。因为对很多模型来说,核心的工作都是做数据的向量特征编码,也可以理解为向量化。因此,中小学要开展人工智能教育,“向量”这一知识点需要早点学习。