双语心理词库理论与研究综述
作者: 王瑜
摘 要:双语心理词库研究历经半个多世纪的发展已经取得了丰硕的成果。文章从双语词汇表征组织、生成和加工机制三个方面,对当前双语表征研究现状做了综合述评,期望对本领域的深入研究有所帮助。
关键词:双语词汇表征;词汇生成;词汇通达
中图分类号:G640 文献标识码:A 文章编号:1002-4107(2022)01-0064-04
双语心理词库研究是语言学、心理学和认知神经科学的一个重要领域,主要研究双语者大脑中两种语言系统的构成、表征组织以及加工特点。在过去的半个多世纪里,尽管研究者们进行了大量的行为实验和神经心理学研究,提出了一系列的双语表征和加工模型,但是仍然没有取得一致性结论。文章从双语词汇表征、语言生成模式和双语加工机制三个双语记忆研究的焦点问题,对已有双语研究结果进行综合述评,希望对将来相关研究有所启示和帮助。
一、双语心理词库研究背景
1953年Weinreich从宏观上将双语者的两种语言之间关系归纳为并列—复合—从属(coordinate-compound-subordinate)三种类型,奠定了双语心理词库研究的基础。根据Weinreich的定义,这三种类型的双语者的主要区别在于他们双语的存储形式不同。“并列型双语者”的大脑中两种语言系统独立存储。以汉英双语者为例, “book”和“书”除了词形不同之外,它们的概念表征也不同。对“复合型双语者”来说,两种语言系统共享概念表征。“book”和“书”只是词形不同,概念表征相同。“从属型双语者”是学会了一种语言(L1)之后,又学习另一种语言(L2)的双语者,L2单词“book”需要通过L1“书”对译词词形与概念表征进行连接。
双语者类型区分引起了研究者们对双语存储问题的关注。20世纪60年代和70年代初,围绕这个问题,早期双语研究者们使用词汇联想和命名、词汇识别和回忆等行为实验方法得出两个相互矛盾的结论:一是双语共同存储,即两种语言的词汇信息与同一概念表征联系;另一个是双语分别存储,即两种语言词汇信息分别与各自独立的概念表征联系。这两种观点各持己见,争论持续到70年代末,以Paradise为代表的一些双语研究者意识到,对语言系统结构认识不足是造成研究结果不一致的主要原因。他们认为语言表征结构分语义概念层表征和词汇层表征,为双语层级表征模型建构提供了可能。
二、双语词汇表征
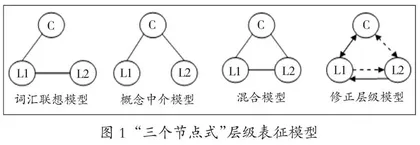
信息加工心理学对双语心理词库理论和方法研究具有重要的意义。利用干扰和启动实验范式进行自动化加工(如扩展激活驱动的自动化加工)实验任务和反应时测量,为概念表征层共享、词汇表征各自独立的双语层级表征结构互动关系提供了依据。经典的“三个节点式”层级表征模型有:词汇联想模型(Word Association Model)、概念中介模型(Conceptual Mediation Model)、混合模型(Mixed Model)和修正层级模型(Revised Hierarchical Model)。如图1所示,“C”表示概念表征节点,“L1”表示第一语言词汇表征节点,“ L2”表示第二语言的词汇表征节点。
这四个模型描述的双语者的双语水平不同,阐释的概念节点、L1词汇节点和L2词汇节点之间的连接强度(又称连接权重)也不同。词汇联想模型认为,二语学习初期,学习者L1词汇节点与概念节点直接连接,L2与L1词汇节点直接连接,但是L2词汇节点不能与概念节点直接连接。也就是说,母语为汉语的英语初学者命名图片“dog”时,先通达L1汉语“狗”,再将其翻译成目标词“dog”。概念中介模型是双语水平平衡的双语者的双语层级表征结构,概念表征节点负责调节L1与L2词汇节点的连接。命名图片“dog”时, L2词汇“dog”被直接通达。混合模型指出,双语者的二语水平不会影响L1、L2词汇节点和概念节点的连接,影响三个节点之间直接连接的是词汇类型(例如:双语词汇中音、形、义都相似的同源词)。修正层级模型是学习者二语词汇表征发展模式,是一个非平衡双语连接模型。模型中,三个节点相互连接,但连接强度不同。因为二语水平低的双语者的L2词汇节点不会直接与概念节点连接,而是以L1词汇节点为中介,所以L2→L1方向词汇节点连接强度大于L1→L2方向的连接强度。L2词汇节点与概念节点直接连接需要经过反复的L2→L1方向词汇节点连接后才能够被建构,连接强度弱于L1词汇节点与概念节点之间的连接强度。
如果说两种语言共享概念表征是实现双语连接的基础,那么语言之间语义相关性就是它的重要表现。语义启动实验是典型的验证语义相关性的实验方法,也是层级表征模型研究中经常使用的实验方法之一。单语语义启动实验逻辑是,如果目标词(dog)出现之前先呈现它的语义相关词(也称启动词,cat),那么目标词的提取速度快于启动词为非语义相关词(tree)时的目标词提取速度。这种现象叫做语义启动效应。根据语义启动效应,双语启动实验中,启动词和目标词分别是两种语言,如果双语共享概念特征,只要启动词和目标词是语义相关词,非目标语的语义相关词也会像单语语义相关启动词那样促进目标词提取。
与语义启动实验原理相似的还有翻译实验。翻译实验通常以图片命名或词汇命名的反应时为基本参照。语言内词汇提取研究发现,词汇命名比图片命名反应时快250ms。研究者认为超出的时间是图片命名比词汇命名多了通达概念表征的过程。依据这个实验原理, Potter 等研究者通过对比词汇翻译速度和图片命名时间,证明了词汇联想模型和概念中介模型。之后,Kroll和 Steward在翻译任务的基础上增加了语义范畴限制, 结果发现,语义范畴干扰现象只出现在L1→L2方向的翻译,从而说明两种翻译方向(L1→L2 方向和 L2→L1方向)有不同的中介连接(见上文)。另外Kroll和Steward的实验出现了母语对二语的迁移作用,由此证明学习者的记忆表征中双语不对称关系是第二语言发展的规律。但是需要我们注意的是,修正层级模型不能代表所有二语学习者双语记忆表征,因为语言发展具有个体差异性。很多因素,例如学习策略、语言使用频率、学习年龄、学习环境以及词汇类型(如同源词或具体词)等,都会影响个体双语记忆表征组织。而且每个双语者心理词库中也可能包含多种类型的心理表征结构[1]。
虽然目前多数研究支持双语层级表征模型认为双语语义概念表征共享,但是跨语言长时重复启动试验研究(Long-term repetition priming)和前摄干扰豁免效应研究(Release from proactive interference)显示双语词库独立表征,例如跨语言长时重复启动实验中法语启动词“chien”不能促进英语对译词 “dog”的识别。然而,这种观点是缺少对实验任务本质认识的表现。重复启动实验是作用在知觉层的语言加工,如果双语同义词拼写相近,就会产生重复启动效应。但是对于双语拼写不同但是意义相近的同义词来说,重复启动效应不可能实现。
Keppel和Underwood采用Brown-Perterson短时记忆(STM)方法,即要求被试者在无练习条件下记忆单词,结果发现,当单词记忆间隔时间相等时,先前所记单词影响后继单词回忆的水平[2]。这种现象被称为前摄干扰(Proactive interference)。基于这种实验方法,Goggin 和 Wickens在对双语者进行一系列范畴或语言转换实验中发现,如果先前词汇记忆加工任务中有语义范畴或语言改变,那么后面词汇回忆时所产生的前摄语义干扰效应就会减弱。他们认为产生前摄干扰豁免效应是因为双语记忆分离。也就是说,因为双语者的两个语言系统独立存储,所以先后记忆不同语言词汇不会产生先后干扰作用。然而,前摄干扰豁免效应通常是语言内语义范畴改变时才出现的效应。Goggin 和Wickens将语言内干扰效应直接套用在双语记忆研究中来证明双语词库独立表征,实际上就是将语言系统转换视作语义范畴改变,忽视了认知和语言系统复杂性问题。
双语词汇表征是动态发展的,分布联结主义网络模型解释了产生双语词汇表征的心理机制。
三、分布联结主义网络模型
与对双语词汇表征的研究热情相比,研究者们对词汇表征的生成问题关注得比较少。分布联结主义网络模型是神经网络计算模型,主张双语表征组织是语言学习的结果。模型主要包括三个层级:输入层(input layer)、内隐层(hidden layer)和输出层(output layer)。输入层和输出层分别负责网络中输入和输出信息;内隐层是中间层,负责存储网络知识表征。学习过程是从输入层接收网络输入信息开始,至内隐层,再到达输出层。学习和训练是调节单元之间关系的过程,是改变单元之间联结权重的过程。因此,分布联结主义网络模型是一种语言习得(学习)机制的涌现(emergent)结果,它解释了双语记忆表征组织类型形成原因。
双语单网络模型(the bilingual single network model,BSN model)、双语简单回馈网络模型(the bilingual simple recurrent network,BSRN)和双语处理自组模型(self-organizing model of bilingual processing,SOMBIP)是三个典型的分布联结主义网络模型。双语单网络模型(BSN model)是一个可指导的(supervised)、从单词的拼写向词义方向激活映射的层级结构。根据该模型,在双语概念表征共享的条件下,双语知识是由网络学习过程中内隐层形成的抽象的语言标记区分。语言标记是一种叫做主要成分分析(principal component analysis)的统计方法,通过它可以识别双语中拼写相近的同形异义词或同源词。双语简单回馈网络模型(BSRN )指出,只要有充足的语言输入,并且语言转换的频率低于0.1%,就会建构双语各自不同的词汇内部表征。双语处理自组模型(SOMBIP)是一个非指导学习(unsupervised learning)网络模型,包括英语和汉语的词汇语音表征和意义表征。学习是自组网图的联结,赫比学习法(Hebbian learning)被用来表达联结方式。双语知识表征的涌现是语料中累计内隐层词义和语音共现的频率和规律的学习过程。
上述三个网络模型都是以统一双语表征体系为基础,认为双语词汇表征组织是学习作用的结果。但是关于如何区分双语词汇层表征问题,BSN模型与BSRN模型和SOMBIP模型不同。BSN模型是基于成年双语者跨语言干扰效应研究得出的“有指导学习”(supervised learning)前馈联结主义结构。它提出的使用显性语言标记区分双语词汇层表征备受争议,因为这是用静态的心理机制解释动态的双语词汇表征组织。从这一点来看,BSRN和SOMBIP模型对双语词汇表征组织生成的解释似乎更合理,它们都认为双语者的两种语言的词汇表征是对输入信息作用后两种语言各自特征的涌现。BSRN模型中,语言输入信息时双语之间各自不同的词汇联结特征可以区分双语的词汇表征;SOMBIP模型中,双语的词汇层表征组织是以不同类型的语音为线索,由输入产生的规律化的产物。
四、双语者的语言加工机制
(一)词汇通达
词汇通达是指从语言记忆系统中提取与输入信息匹配的词的过程。双语词汇通达与双语表征联系紧密。围绕双语者的两种语言的拼写、语音层、语义层及概念层之间关系问题,有两种极端的假设:词汇选择性通达假设和词汇非选择性通达假设。
词汇选择性通达假设是指在双语者语言加工过程中,只有目标语的相关词汇表征被激活和加工。有研究者认为,受双语自动输入开关(an automatic operating input switch)机制的影响,双语者在使用一种语言时,另一种语言处于关闭状态。另外,语码转换实验发现,被试者加工混合语码信息(两种语言编写的段落或句子)比加工单语信息(一种语言编写的段落或句子)速度慢。根据词汇选择性通达假设,语言搜索会产生时间消耗。词汇提取开始时是以先加工的语言优先选择原则,按照顺序搜索目标语。每次语言转换都要重新搜索目标语,自然会产生时间消耗。然而,在语言交际中,双语者经常需要语码转换。如果语码转换需要时间消耗,那么势必会影响正常语言交流的顺畅性。而且,Beauvillain和Grainger依照输入开关系统假设,对英—法双语者进行了语码转换实验研究[3]。通过对比单语—混合语词汇判断的反应时效应,他们发现当刺激词的拼写具有语言特定性时,语码转换时没有时间消耗。Kolers等人的实验研究所使用两种语言编写的句子或段落是实验者主观编造的,与实际交流不符。