神经网络在移动恶意软件检测中的应用与优化研究
作者: 邓启润
摘要:该研究探索了基于神经网络的移动恶意软件检测方法,并通过优化策略提升了模型性能。研究在公开数据集上深入分析了恶意软件的权限特征,比较了几种常见模型在检测中的表现,发现神经网络在处理复杂数据时表现卓越。通过优化学习率,该模型的召回率提升至 97.81%,显著增强了其在恶意软件检测中的敏感度。
关键词:神经网络;恶意软件检测;移动应用安全;学习率优化
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2025)09-0048-03 开放科学(资源服务) 标识码(OSID) :
恶意软件的种类和复杂性日益增加。根据卡巴斯基实验室的报告,2022年Android设备所遭受的恶意软件攻击比前一年增长了35%[1]。传统的恶意软件检测方法主要有两类:基于签名的检测和基于行为的检测。基于签名的方法依赖于已知样本的签名库,虽然检测速度快,但对于未知或变种恶意软件则失效[2]。
相比之下,基于行为的检测通过分析应用的行为模式来识别潜在威胁,尽管适应性更强,但在资源有限的移动设备上,高计算成本仍是显著挑战[3]。
神经网络模型在恶意软件检测中逐渐受到关注。这是因为它在特征提取和复杂数据处理方面表现卓越,具有较高的准确性和鲁棒性[4]。然而,训练过程中通常涉及大量参数,如何有效优化以提升检测性能仍是一个挑战。
本研究的目的是探索神经网络在移动恶意软件检测中的应用,并通过优化模型提升检测性能。主要贡献有两点:一是探索神经网络技术在移动应用安全领域的应用,提供一种高效的恶意软件检测解决方案;二是通过研究优化策略,探索如何在资源受限的移动环境中实现高效的深度学习模型,这对构建移动环境中的安全系统具有一定的指导意义。
1 数据集分析
本研究使用公开的 Android 应用程序权限数据集。该数据集包含多个 APK 文件及其对应的权限信息,以及每个APK 是否为恶意软件的标签。数据集共包含 5 654个样本,恶意软件占50.32%,良性应用占49.68%,这一均衡性为后续模型训练和评估提供了可靠基础。
数据集中的每个样本包含72个权限,这些权限标识了应用程序在安装或运行过程中可以请求的系统资源或功能。同时,标签信息(即是否为恶意软件) 为二元分类任务提供了明确的目标变量。
1.1 数据预处理
完成数据清洗后,进行特征分析。考虑到权限特征的重要性,我们计算了各权限与目标变量(是否为恶意软件) 之间的相关性系数。通过相关性分析,识别出与恶意软件高度相关的关键权限。这些权限通常在恶意软件中被滥用,以实现信息窃取或发送恶意信息。
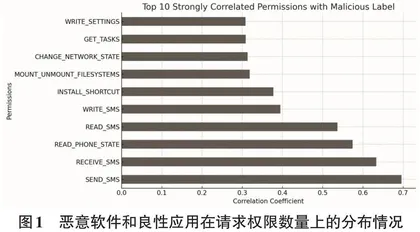
在数据的探索性分析中,我们发现一些权限特征间存在高度相关性。例如,READ_SMS 和 WRITE_SMS 权限通常同时出现在恶意软件中,这反映了恶意软件在窃取和修改用户短信过程中的行为模式。为进一步分析这些特征的分布情况,我们绘制了不同类型应用在各权限请求数量上的分布图(见图1) 。
如图1所示,恶意软件与良性应用在权限请求数量上的分布存在显著差异。为了执行复杂的恶意行为,恶意软件通常会请求更多的权限,以便窃取用户信息、发送高额短信。
1.2 权限特征分析
为了直观理解恶意软件与良性应用之间的权限请求差异,统计了最常请求的前十个权限。结果显示,INTERNET权限在绝大多数应用中被请求,这表明网络连接是现代移动应用的基础功能。然而,SEND_SMS、READ_PHONE_STATE 等权限在恶意软件中被请求的频率明显更高,这暗示这些权限可能是恶意软件实施攻击的关键手段。
1.3 权限与恶意标签的相关性分析
为深入分析权限特征与恶意标签的关系,计算了各权限与恶意软件标签的皮尔逊相关系数。结果显示,SEND_SMS、RECEIVE_SMS 和READ_PHONE_STATE等权限与恶意标签之间呈现较高的正相关性。这表明这些权限在恶意软件中的使用频率显著高于良性应用。因此,在后续模型训练中,这些权限将成为区分恶意软件与良性应用的重要特征。同时,通过对数据集的深入分析,识别了可用于恶意软件检测的重要权限特征。
2 模型的选择与实现
在恶意软件检测领域,传统机器学习算法因其低计算成本和良好的可解释性,常被用于早期研究。本研究选择了几种常用的机器学习算法进行对比分析,包括逻辑回归、决策树和随机森林模型。之后,使用神经网络的多层感知器(MLP) 对数据集进行训练,以便对各模型性能进行对比。
模型性能评估指标包括准确率、精确率、召回率和F1分数。准确率衡量模型判断应用为恶意软件或良性应用的总体概率。高精确率表明模型在预测恶意软件时误判较少,有助于减少误报,进而保护用户体验。召回率则衡量模型能够检测出更多恶意软件的能力,这在恶意软件检测任务中至关重要。F1分数是精确率与召回率的调和平均值,平衡这两个指标是评估模型性能的一项重要标准。
2.1 逻辑回归
逻辑回归是一种经典的二元分类算法,通过学习数据特征与目标变量的线性关系,输出一个表示属于某类别的概率值。由于模型简单且易于解释,逻辑回归在早期恶意软件检测研究中得到了广泛应用。在本研究数据集上,逻辑回归模型的召回率达到96.72%,但在处理复杂非线性特征时表现有所欠缺。
2.2 决策树
决策树是一种基于树状结构进行分类的算法,通过递归分割数据,形成多层决策节点和叶节点的模型。决策树具有较强的解释性,并能够处理非线性特征。然而,单一决策树模型容易过拟合,特别是在样本数据中存在噪声的情况下。在本研究中,决策树模型在恶意软件检测任务中的召回率为96.35%,略高于逻辑回归模型。
2.3 随机森林
随机森林通过集成多棵决策树,并利用多数投票的方式输出最终的分类结果,从而提升模型的鲁棒性和准确率。在本研究中,随机森林模型的召回率达到96.72%,显著高于逻辑回归和单棵决策树模型。
2.4 神经网络模型的选择与实现
神经网络模型由于其强大的特征学习能力和非线性处理能力,逐渐成为恶意软件检测领域的研究热点。通过多层神经元的连接及激活函数的作用,神经网络能够有效捕捉复杂模式和关系,实现更精准的分类。
多层感知器(MLP) 是基本的神经网络结构,通常由输入层、一个或多个隐藏层以及输出层组成。每层神经元通过加权链接与上一层神经元相连,并通过激活函数引入非线性。本研究使用包含100个神经元的单隐藏层MLP模型进行恶意软件检测。该模型的准确率为96.02%,与随机森林模型相当,但其召回率达到了97.08%,在处理高维和复杂数据时表现更为突出[5]。
各模型训练后的性能指标对比如下:
随机森林与神经网络模型在多数指标上表现优异,尤其在准确率和F1分数方面,因此适合用于构建高效且可靠的恶意软件检测器。这些模型能够在误报和漏报之间实现良好平衡。
2.5 随机森林与神经网络模型的性能对比
在高维数据和复杂特征的场景下,神经网络模型展现出更强的适应性与泛化能力。虽然随机森林在精确率方面略优于神经网络,但在处理复杂数据时,神经网络的表现更为稳定。同时,虽然神经网络模型在训练阶段的计算复杂性和内存占用高于随机森林,但在推理阶段的资源消耗较低,因此更适合移动应用场景。
3 模型的优化
在训练过程中,学习率的选择对神经网络模型的收敛速度和最终性能至关重要。学习率过大可能导致模型训练振荡甚至发散,而学习率过小则会使训练过程缓慢,难以收敛到全局最优解。为了找到合适的学习率,我们使用了学习率范围测试(Learning RateRange Test) ,逐步增大学习率,观察损失函数的变化,最终确定最佳学习率。
3.1 学习率范围测试
我们将学习率从极小值逐步增大至1e-1,并记录每个学习率下损失函数的变化(见图2) 。图中显示,当学习率接近0.01时,模型的损失函数值最低且变化平稳,这表明该学习率有效地推动了模型向全局最优解收敛[6]。
3.2 优化后的模型性能
将学习率调整为0.01后,我们重新训练了神经网络模型,并将其性能与初始模型进行了对比(见表2) 。
观察召回率的变化,优化后的模型在性能上有一定提升。优化后的模型的召回率提高至97.81%,表明其在检测恶意软件方面更为敏感。这里主要关注召回率指标的变化,是因为本研究的任务目标是尽可能捕获所有的恶意软件,即希望减少漏报(FN) 。即使准确率和精确率略有下降,也要先确保系统安全。
4 结束语
本研究旨在探索和优化基于神经网络的移动恶意软件检测方法。通过与多种检测技术的比较,发现神经网络模型在检测复杂恶意软件样本方面具有明显优势。经过学习率优化后,模型在恶意软件检测任务中更敏感,有效减少了漏报。然而,尽管本研究在优化神经网络模型用于恶意软件检测方面取得了一定进展,但仍存在进一步改进的空间。未来的研究可以集中于开发更轻量化的神经网络模型,并探讨模型的剪枝和量化等技术,以使其更适合在资源有限的移动设备上部署。