本地算力服务器支持下的人工智能教学和实践
作者: 谢作如 林淼燚中图分类号:G434文献标识码:A论文编号:1674-2117(2025)09-0016-04
教育部办公厅2024年发布的《关于加强中小学人工智能教育的通知》明确提出,要通过人工智能课程培养学生的创新精神与问题解决能力。然而,在中小学推进人工智能实践教学的过程中,算力匮乏始终是制约课程开展的关键瓶颈。商业云服务高昂的成本、外网连接的不确定性以及学生终端性能的局限性,使得许多学校在人工智能实验教学中只能停留在浅层体验阶段。
为突破这一瓶颈,笔者设计了一套基于算力支持的单元课程,帮助学生理解人工智能技术的核心原理和应用逻辑。下面,笔者以单元的最后一课《Embedding和文本分类》为例,辨析本地算力服务器在中小学人工智能课堂中的价值与意义。
核心内容设计:让计算机读懂文字
人类通过字词的排列组合理解语义,而计算机同样需要用各种算法提取出文字特征来理解文本。早期人们通过统计词频来分析文本的特征,现在常用词嵌入技术,其流程是先将字词转换为多个数值的列表(数学上的向量)(如下页图1),在经过深度学习模型训练后,语义相近的词数值也更加相近。
以常见的词嵌入模型为例,训练一个包含10万词汇的Word2Vec模型需要进行数百万次矩阵运算;而基于Transformer架构的现代语言模型(如GPT-3等),其参数规模已达1750亿(175B)甚至更大,也需要将字词从文本转为数字向量,再判断可能的输出词,其单次推理就需要调用数以亿计的参数。这些计算任务远超普通教学终端的处理能力,因此,强大的算力支持变得至关重要,只有具备足够的计算能力,才能让计算机快速处理海量文本数据,真正实现从“能读”到“会懂'的跨越。
本课是“人工智能跨学科项目入门”单元的总结课,本单元涵盖机器学习基础、感知机、神经网络等核心概念(如图2),并通过实践项目帮助学生设计解决实际问题的智能应用。
学生已具备一定的机器学习知识,熟悉词嵌入和向量比较原理,但尚未将文本向量化与分类模型训练结合。学生熟悉OpenHydra平台和Jupyter编辑器,可完成复杂模型训练任务并分析报错原因。
基于以上考虑,确认本课教学目标如下。
信息意识:培养对人工智能技术的敏感性和认知能力,理解词嵌入和文本分类的技术原理及其在实际问题中的应用价值。
计算思维:通过调用预训练模型和优化本地数据集,培养分析问题、设计算法、优化模型的能力,提升逻辑推理和问题解决能力。
数字化学习与创新:借助本地算力平台和编程环境,能够高效完成文本分类任务,自主探索机器学习算法,培养技术实践能力和创新能力。
信息社会责任:通过解决校园管理中的实际问题,理解人工智能技术的社会意义,培养技术伦理意识和社会责任感。
硬件配置与本地算力教学平台
针对上述问题,笔者所在学校科创团队采购了算力服务器,在其基础上部署了校本算力管理平台,不仅解决了算力匮乏的问题,还极大地提升了教学效率。
1.硬件
算力服务器专为处理复杂的计算任务而设计,它通常配备高性能的GPU(图形处理单元),如笔者所在学校配置的算力服务器配有两张TeslaT4显卡,拥有32GB显存,这些GPU能够加速深度学习和机器学习算法的训练过程,使学生能够在短时间内完成复杂的计算任务。服务器操作系统一般选择Linux系统,也有配备Windows系统的工作站可供选择,适合初学者和对特定软件有需求的用户。
在预算范围方面,根据市场调研和实际需求,中小学校部署一套能满足课堂深度学习教学的本地算力服务器的预算通常在2万元至5万元之间。
2.OpenHydra平台的优势
在拥有硬件后,还需安装特定软件以实现算力分割功能,才能支持多个小组同时开展人工智能实验。算力分割允许多个用户或任务共享同一物理计算资源,而不会相互干扰,每个虚拟计算单元可以独立运行不同计算任务,实现资源高效利用和任务并行处理。平台中教师管理页面如图3所示。
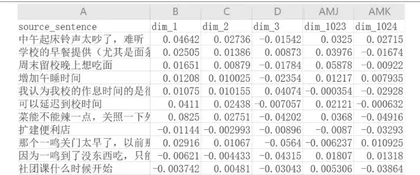
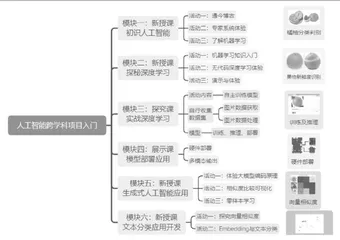
图2“人工智能跨学科项目入门”单元设计框架
除算力分割功能外,平台还支持常规教学模块与课程资源模块。学生可以在浏览器中访问平台,点击创建容器开始实验(如图4)。每个账号拥有独立的编程环境与文件目录,也可为多人小组分配同一个账号进行协作实验。
在传统教学模式下,教师需在不同设备上配置实验环境,耗时费力且容易出现兼容问题,而容器化技术实现了“一次配置,多次使用”,显著提升了教学效率。
教学过程与活动设计
1.课题导入与情境创设
课堂伊始,教师通过校园管理中的真实场景导人:校长信箱每月收到数百条学生反馈,涵盖食堂、课程、宿舍等多个领域。接着,提出问题“如何让计算机自动理解这些文本并精准分类”,通过课前收集的待分类数据集,让学生直观感受文本分类技术的应用价值。
2.预训练模型调用
(1)词嵌入原理讲解
本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:xxjy20250905.pd原版全文
教师先通过动画演示词嵌入原理,结合物理中向量运算类比解释语义运算(如"国王-男人+女人≈ 女王"),让学生体验向量运算的逻辑,再使用可视化工具展示字词之间的相关性,帮助学生理解语义相近的词在向量空间中的位置关系。
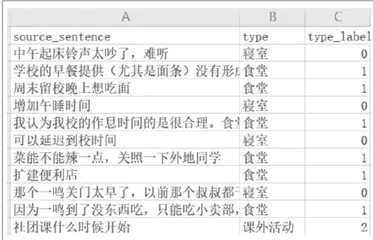
在随后的实践活动中,学生通过调用互联网上的预训练模型,对校长信箱文本数据进行向量化与文本分类,学生能够在文件目录中看到简单分类后的结果(如下页图5)。
在这一过程中,本地算力服务器发挥了关键作用:上百条文本的向量化过程原本需要数十分钟,如今在学生的浏览器上仅需数秒即可完成,让学生能够实时观察到运算
图4学生在编程环境中访问教师上传的公共学习资源
多层感知机(MLP)和 1sec.ago 鑫尾花数集因其样本。在中、断、分类问题eML单,一了多入门级机器学习数圆基于果物的K近邻分类.ipy.. 1 sec. ago 尾花的三个品种进行识别,验证多层感知机(MLP)的分类性能。圆朴素贝叶斯和天气预报.p.. 1 sec. ago圆支持向量机(SVM)和手. 1 sec. ago 1)实验资源·data/iris.csv2)实验目的·通过自主探究,可以理解多层感知机的基本原理,知道多层感知机可以运用鸢尾花分类任务:·通过使用BaseML搭建多层感知机分类器,掌握搭建多层感知机分类器的基础代码:·通过对模型参数的调整,能够解释重点参数的含义以及对于模型效果的作用。3)实验内容0实验一:使用多层感知机搭建并训练鸢尾花分类模型 寸SimpleO 01 Python 3 (ipykernel) ↓ ldle Mode: Command Ln1,Col1多层感知机(MLP)和尾花分类.ipynb1
(2)实践操作
结果结果。
3.模型的二次优化
虽然通过调用现成模型能够获取分类结果,但仍存在分类错误的问题。如“一鸣”便利店实际开设位置在食堂附近,但对于互联网上的模型,词库中并不存在该建筑的地理位置信息,有关“一鸣”的建议就被随机分到了“食堂”“寝室”等任意分类方向,此时就需要手动标注数据,生成一个本地化的数据集。
经过了“自动生成类别”的操作,再对上图中的标签进行微调,之后就可以将数据投入机器学习模型,让其再次分类(如图6),得到一个更加准确的机器学习模型。
为了让学生快速回忆起机器学习的相关训练流程,教师在公共课程文件夹中提供了“常见机器学习分类方法及其程序实现”的资源,每个程序文件中都包含了完整的算法讲解与实际情境。资源目录如下: ① 多层感知机(MLP)和鸢尾花分类; ② 基于果物的K近邻分类;③ 朴素贝叶斯和天气预报; ④ 支持向量机(SVM)和手势分类(关键点检测)。
学生两人一小组,每组自行选择一种机器学习方法进行学习,在学习完简单案例后,替换代码与数据集,用机器学习的算法完成文本数据的分类。
4.展示分享
在课堂最后,在教师提供的资源支架下,大部分小组能训练出一个机器学习模型,在程序中看到新模型的分类效果。教师邀请部分小组展示分类模型应用情况,分享模型优化策略。
课后反思:中 小学人工智能教学的 算力困境与突破
算力是人工智能教育的底层支撑,但中小学校长期面临算力匮乏的困境。笔者曾尝试使用云端平台进行模型训练,但由于并发限制和网络波动,学生经常无法完成实验。这种“时断时续”的教学体验严重限制了课程开展的深度与广度。
本地算力支持下的课堂教学能高效训练模型,在结合适当的算力管理平台后,还能拥有如下优势:教师统一分发账号,免去注册与登录流程,保障学生学习文件归属与连续性;虚拟助教提供个性化指导;丰富的公共课程与数据集助力学生自主学习跨学科内容。
许多中小学教师对算力部署存在顾虑,认为其部署流程复杂且成本高昂。然而,实践证明,本地算力服务器的部署并不复杂(购置设备后安装操作系统),成本也在可承受范围内。通过算力支持,学生能够深入参与模型训练和算法优化,真正实现从“体验”到“实践”的转变。算力不仅是技术支撑,更是解决人工智能课堂教学“浅层化、表面化”难题的利器,助力青少年在基础教育阶段了解“数据收集一模型训练一模型部署”的人工智能应用逻辑。
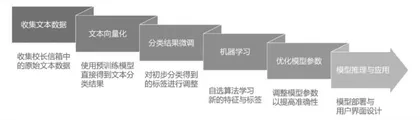
图6课程设计中的文本分类逻辑
本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:xxjy20250905.pd原版全文