以数据、算法和算力为核心的高中人工智能实验教学
作者: 刘宜萍中图分类号:G434文献标识码:A论文编号:1674-2117(2025)09-0048-06
背景和现状
“人工智能初步”作为高中信息技术课程的选择性必修内容,旨在让学生学习描述典型人工智能算法的实现过程,并通过搭建简单的人工智能应用模块,了解设计与实现简单智能系统的基本过程与方法,从而增强学生利用智能技术为人类发展服务的责任感。但是,目前中小学人工智能教育还存在AI课程资源匮乏、教学设备及平台陈旧、AI教学师资不足以及GPU算力资源不足等问题,导致一线教师在引导学生运用数据、算法和算力解决实际问题的能力培养上,还面临一些挑战。
教育部教育技术与资源发展中心(中央电化教育馆)发布的《中小学实验教学基本目录(2023年版)》(以下简称《基本目录》)不仅为《普通高中信息技术课程标准(2017年版2020年修订)》在实践教学中的实施提供了具体指导,而且鼓励教师在实验技术和方法上进行创新,旨在提升学生解决复杂问题的能力。《基本目录》明确了通过人工智能实验教学提升学生的实践技能和创新思维的路径。通过实验教学,重点培养学生在以数据、算法和算力为核心的项目创作中解决实际问题的能力。
概念与模型
在这样的背景下,项目式学习在人工智能教育中就显得尤为重要,它不仅能够激发学生的学习兴趣,还能够提供一个实践平台,让学生在解决实际问题的过程中,深入理解和掌握人工智能的核心概念。在人工智能项目式学习中,数据、算法和算力是实现项目成功的三个关键要素,它们在人工智能实验教学中扮演着至关重要的角色。因此,笔者提出了在人工智能项目式学习中构建以数据、算法和算力为核心的实验教学模型(如下页图1),旨在通过实验深化学生对数据、算法和算力三要素的理解。
人工智能项目式学习涵盖了从项目需求分析到项目方案设计,再到项目探究与实施,以及最终的项目展示与评价等关键环节。在项目探究与实施阶段,采用以数据、算法和算力为核心的人工智能实验教学。该实验是学生掌握知识点和技能点、落实核心素养和达成学业要求的重要环节,可将其细分为以下几个核心步骤。
1.数据采集
① 数据来源选择:指导学生根据项目需求挑选合适的数据源。② 数据收集方法:讲解网络爬虫、API、调查问卷、拍摄等数据获取手段。
2.数据预处理
① 数据清洗:教授学生识别和处理缺失值、异常值和重复数据。② 特征提取:指导学生从原始数据中提取有助于模型学习的特征。
3.算法选择与理解
① 算法介绍:阐述贝叶斯分类、线性回归、决策树、SVM、神经网络等。 ② 算法匹配:依据项目和数据特点,引导学生挑选适宜算法。
4.模型训练
① 选择平台和工具:选择适合中小学AI教育的工具或学习平台,构建训练环境。 ② 算法实现:应用选定算法,执行模型训练任务。
5.模型测试与评估
① 性能评估:运用准确率、召回率、F1分数评估模型。 ② 参数优化:调整参数以提升模型效能。
6.算力资源应用
① 算力硬件基础:讲解算力基 础,对比CPU与GPU。 ② 云服务算
力:感受云服务对AI项目带来的便利。 ③ 算力资源意识:教授优化算力资源使用效率。
7.模型部署与应用
① 模型部署:将训练好的模型部署到不同的平台和环境中。② 模型应用:将模型应用到实际生活中解决实际问题,并监测效果和优化。
通过这种以真实情境为基础的项目探究和实施,学生能够深化对数据、算法和算力的理解和应用,实现从理论到实践的转化。这种学习方式不仅有助于学生深入理解人工智能技术,而且能够提升他们解决复杂问题的能力,培养人工智能素养。
应用与实践
下面,笔者以粤教版高中信息技术《选择性必修4人工智能初步》第三章“3.2贝叶斯分类器”中的项目范例“剖析垃圾邮件智能分类系统”为例,阐述在项目式学习中如何开展以数据、算法和算力为核心的人工智能实验教学。
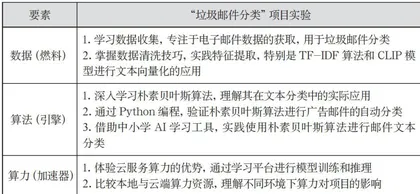
1.“垃圾邮件分类”项目实验中的数据、算法和算力
在“垃圾邮件分类”项目实验教学中,将数据、算法和算力三个核心要素与教学活动紧密结合,以确保学生在项目实践中能够全面理解和掌握人工智能的核心概念和技术,具体如下页表所示。
2.选择实验平台和工具
① 选择浦育-OpenInnoLab平台,借助平台上的中小学AI学习工具XEdu,帮助学生体验文本数据处理,实现邮件文本向量化,体验使用贝叶斯算法进行模型训练和推理的过程。
② 本地安装中小学AI学习工具XEdu,在本地完成数据处理、模型训练和推理,帮助学生体验比较本地CPU算力和云服务CPU、GPU算力的不同。
3.实验步骤设计
(1)数据采集
① 数据来源选择:引导学生识别和选择与垃圾邮件分类相关的数据集,如公开的邮件数据集或通过模拟环境生成的数据。 ② 数据收集方法:学习如何通过网络爬虫收集电子邮件数据,或使用API从电子邮件服务提供商处获取数据。

(2)数据预处理
在人工智能项目中,数据预处理是至关重要的一步,它直接影响到模型训练的效果和预测的准确性。数据预处理具体包括数据清洗和特征提取。 ① 数据清洗:学习识别和处理垃圾邮件数据中的缺失值、异常值和重复邮件。 ② 特征提取:将文本数据转换为数值向量的过程,这对于计算机理解和处理文本内容至关重要。
本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:xxjy20250915.pd原版全文
本项目引导学生深入学习和体验两种主要的文本特征提取方法:TF-IDF算法和CLIP模型的文本嵌入。
方法一:运用TF-IDF算法进行文本特征提取。
理论学习:学习TF-IDF算法的原理,包括文本分词、构建词典、计算词频、去除停用词,以及计算TF-IDF值。
实践操作:引导学生使用Python实现以TF-IDF算法进行文本特征提取,通过如图2所示的步骤完成文本向量化。
方法二:运用CLIP模型进行文本向量特征提取。
为了帮助计算机理解文本,一般是通过“特征提取”的方式将它们转换为数字向量,这个过程可以叫做向量化。
理论学习:CLIP是一种基于深度学习的多模态预训练模型,它通过对比学习的方式在大量文本数据上进行训练,从而能够捕捉文本的丰富语义和上下文关系。本项目选用中小学AI学习工具XEdu集成的XEduHub,其内置了CLIP模型,提供了embedding_text文本特征提取任务,实现文本向量化。
理论验证:为帮助学生理解词向量能够捕捉单词的语义信息,使得相似意义的单词在向量空间中位置接近,并且可以做简单的计算。例如,“猫”和“狗”比较接近,而“猫”和“飞机”相对远一些。那么从意义上看,“国王”(King)和“女王”(queen)的最大区别是不是性别不同?设计验证实验,验证“国王”的词向量减去“男”的词向量,再加上“女”的词向量,是否与“女王”的词向量接近(如图3),

验证实验结论:两个向量相似度很高,达到了“0.9216038”。可见公式“v("国王")-v("男")+v("女")\~v("女王")”的预测是成立的。从而证明了CLIP模型在处理中文文本特征提取时的有效性,以及词向量能够捕捉单词的语义信息,使得相似意义的单词在向量空间中位置接近。
实践操作:使用XEduHub进行词向量获取与文本特征计算,通过如图4所示的步骤完成邮件文本向量化。
两种方法的比较:TF-IDF算法在处理文本数据时,更注重词语的统计信息,而CLIP模型则能够捕捉更深层次的语义信息。相比之下,TF-IDF算法可能无法直接体现这种语义层面的接近性。
两者各有优势,对于资源有限或数据集不是特别大的项目,TF一IDF可能是一个快速且有效的选择。对于需要深层次语义理解的项目,CLIP模型能够提供更丰富的语义特征,有助于提高分类器的性能。
(3)算法选择与理解
算法介绍:介绍适合中文文本分类的算法,如朴素贝叶斯算法、支持向量机算法、神经网络等。
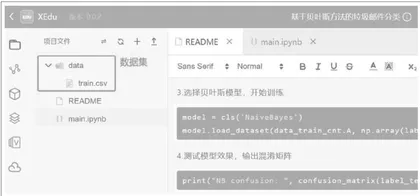
算法匹配:根据垃圾邮件分类的特点,本项目选择朴素贝叶斯算法。
理论学习:学习朴素贝叶斯分
课程教学
类器进行文本分类的原理。为了深入理解这一分类器,组织学生学习与其相关的数学原理。引导学生利用他们在数学课程中已经掌握的概率论知识,学习贝叶斯公式,理解朴素贝叶斯分类器的“朴素”是基于特征条件独立假设,并根据最大后验概率进行分类。了解朴素贝叶斯分类器的类型,即高斯模型、多项式模型和伯努利模型。
理论验证:在浦育平台或本地环境用Python编程实践,用朴素贝叶斯公式进行广告邮件的分类(如上页图5)。学生从理论到实践,学会如何用朴素贝叶斯算法进行文本分类。
(4)模型训练
在浦育平台或者本地环境,学习用XEdu的BaseML库中的朴素贝叶斯算法,进行垃圾邮件分类的模型训练,如图6所示。
(5)模型测试与评估
① 性能评估:使用混淆矩阵来评估垃圾邮件分类模型的性能。混淆矩阵提供了模型预测的详细视图,包括真正例(True Positives,TP)、假正例(False Positives,FP)、真反例(True Negatives,TN)和假反例(False Negatives,FN),从而可以计算出准确率、召回率和F1分数等指标来评估垃圾邮件分类模型的性能(如图7)。模型测试效果可视化图如图8所示。
② 参数优化:根据混淆矩阵的结果,可以识别模型在哪些类别上存在误差,并据此调整模型参数以提高对垃圾邮件的识别准确率。
从结果可见,TP和TN的比例很大,说明效果不错,运行结果准确率为0.90,召回率为0.60,F1分数为 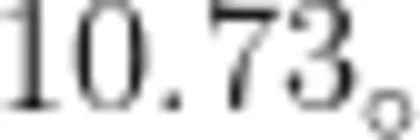
作为本项目的拓展任务,鼓励学生体验XEdu的BaseML库中的SVM、KNN等算法,以及XEdu的BaseNN,均可快速便捷地完成邮件文本分类模型的训练、测试和评估。同时让学生比较不同算法下,邮模型部署到云服务器、树莓派或其他单板计算机上,以便实现垃圾邮件分类系统的远程访问和操作。这样的实践不仅加深了学生对机器学习算法的理解,而且提升了他们应用AI技术解决实际问题的能力。
本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:xxjy20250915.pd原版全文