基于PCNN-Attention的土壤肥力关系抽取研究
作者: 季丰 周乐乐 张彩丽 任竹 刘楠楠 陈磊
摘要 关系抽取旨在抽取文本中实体间的语义关系,是知识图谱构建和信息抽取中的一个关键环节。针对中文土壤肥力文本中语法结构复杂、指标类型较多、同一指标描述方式不同等问题,提出一个基于结合注意力机制的分段卷积神经网络(PCNN-Attention)的土壤肥力关系抽取模型,模型利用分段卷积神经网络实现关系抽取,并在此基础上添加了注意力机制,以提高关系分类的准确性。在构建的数据集中,该模型对多种土壤肥力关系进行抽取,准确度、召回率、F1值加权平均值分别达到了89%、89%、88%,验证了该方法的可行性和有效性,能够满足土壤肥力知识图谱系统构建的需求。
关键词 土壤肥力;PCNN;注意力机制;关系抽取;知识图谱
中图分类号 TP 391 文献标识码 A 文章编号 0517-6611(2022)17-0216-03
doi:10.3969/j.issn.0517-6611.2022.17.054
开放科学(资源服务)标识码(OSID):
Soil Fertility Relation Extraction Based on PCNN-Attention
JI Feng,ZHOU Le-le, ZHANG Cai-li et al
(Institute of Agricultural Economy and Information, Anhui Academy of Agricultural Sciences, Hefei, Anhui 230001)
Abstract Relationship extraction aimed to extract the semantic relationship between entities in the text, which was a key link in the construction of knowledge map and information extraction. Aiming at the problems of complex syntax structure, many index types and different description methods of the same index in Chinese soil fertility text, we proposed a soil fertility relationship extraction model based on PCNN-Attention, the model used piecewise convolution neural network to extract relationships, and added an attention mechanism to improve the accuracy of relationship classification. In the data set constructed, this model extracted a variety of soil fertility relationships and the weighted average values of accuracy, recall and F1 value reached 89%, 89% and 88% respectively, which verified the feasibility and effectiveness of this method. It could meet the needs of the construction of soil fertility knowledge map system.
Key words Soil fertility;PCNN;Attention mechanism;Relation extraction;Knowledge mapping
在农业生产的过程中,准确、迅速地获取土壤肥力相关数据,进行综合评估与分析,对精准农业生产具有重要的意义。随着时代的进步,计算机技术在农业生产领域得到了普遍的应用。利用知识图谱构建土壤肥力知识问答系统,能够有效、快速获取土壤肥力的相关数据,有助于开展精细化农业生产。
关系抽取(Relation Extraction,RE)是知识图谱构建中的重要环节,具有关键的理论意义和丰富的应用前景,为多种应用提供重要的支持。关系抽取主要负责在命名实体识别的基础上,抽取实体间的语义关系,组成实体A、关系、实体B的结构形式。一个完整的RE系统包含3部分:实体识别(用于抽取文本中的实体)、实体链接(将抽取的实体和已有的知识图谱关联)、关系分类(根据上下文对实体关系进行分类)。
在中文土壤肥力相关的文本中,存在“一个文本中存在多种指标类型”“有些存在关系的实体之间距离较远,抽取困难”“文本中对同一种指标的描述方式不一样”等问题,传统的关系抽取方法效果一般,针对这类问题,笔者提出了一种基于PCNN-Attention的土壤肥力关系抽取方法,能够较好适用于土壤肥力领域的文本,满足土壤肥力知识图谱系统构建的需求。
1 相关研究
关系抽取的方法大致有监督学习、半监督学习及无监督学习3类。其中监督学习使用的数据集通常经过完全正确的标注,因此只需要对关系进行分类即可。半监督学习是通过人工部分标注文本,从而构建模板,通过模板选取实力组成训练集,这种方法受到模板构建和规则的影响,会产生噪声影响结果,从而使数据精确度较低 [1]。 无监督学习不需要进行人工标注,而是利用语料中的冗余信息进行聚类,通过结果判断关系,但由于聚类方法对关系的描述不够准确,无监督学习通常无法取得精确的关系抽取效果。
监督学习方面,2013年Liu等[2]提出了使用卷积神经网络进行关系抽取。与传统方法相比,提高了准确度。 2014年Zeng等[3]改良此方法,对输入的词向量进行预处理,同时加入了实体的词汇特征,优化了关系分类的效果。之后,Zhang等[4]提出使用循环神经网络进行关系分类,效果显著优于卷积神经网络。Zhou 等[5]借助长短期记忆人工神经网络,并添加注意力机制,提高了分类的准确度。Zhu等[6]尝试将注意力机制与卷积神经网络相结合,在英文数据集中取得了不错的效果。在半监督学习方面。2015年Zeng等[7]借助多示例学习方法降低噪声,并优化了远程自动标注导致的数据错误问题。虽然降低了噪声对于关系分类的干扰,但也遗失了部分数据。Lin等[8]在此基础上添加注意力机制,在降低噪声影响的同时,提高了数据的利用率。
目前英文数据集上的关系抽取研究较为成熟,而因为中文数据集的缺失,中文关系抽取领域研究较薄弱。Wu等[9]结合注意力机制和卷积神经网络尝试进行中文关系抽取,在中文文本数据上提升了准确性。丁泽源等[10]利用结合注意力机制的双向长短期记忆网络实现关系抽取,在中文生物医学领域得到了不错的结果。姚博文等[11]针对中文人物关系领域的文本中语法结构复杂,文本语义特征不明显的问题,通过预训练模型较强的语义表征能力生成词向量,并将文本句子分层次进行特征提取,在中文人物关系数据集上验证了较好的准确性。
从早期基于模式匹配的关系抽取到后来基于机器学习的关系抽取,实体关系抽取得到了广泛的关注。目前随着以深度学习为基础的人工智能潮流席卷全球,自然语言处理也取得了突破进展。深度学习下实体关系抽取有效改善了传统标注工具的自身缺陷,取得了良好的效果,并成为近些年研究的热点与关键。然而实体关系抽取至今仍面临许多挑战,如实体语义关系的复杂性、句与句之间实体关系的模糊性、数据规模不足与模型学习能力的冲突等都制约着实体关系抽取的发展。
2 基于PCNN-Attention的关系抽取
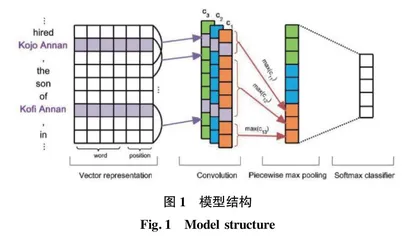
采用PCNN-Attention模型实现关系抽取,模型结构如图1所示,包括BERT预训练语言模型、卷积层、分段池化层以及Softmax分类层。
2.1 BERT预训练语言模型
本层的作用是对文本进行向量化,与其他模型有所区别的是,该研究使用的PCNN模型同时考虑单个实体词语义信息和每个实体词与其他词的相对位置,因此需要分为词向量化和位置向量化2步,从而将输入的文本转化为向量形式,以便于计算机进行处理。
训练数据集为中文土壤肥力领域文本,为了便于计算机的处理,利用BERT预训练语言模型进行词向量化,训练得到每个词对应的向量。
通过以下方法对句子向量化:首先,将句子拆分为数个单词,并将2个实体词作为基准词,将其在句子中的位置视为0,分别计算其他词相对于基准词的位置。例如,“五莲县土壤全氮含量为0.82 g/kg”,可以分为“五莲县”“土壤”“全氮”“含量” “为”“0.82 g/kg”6个词,其中“五莲县”和“0.82 g/kg”为实体词,则其他词关于“五莲县”的相对位置为[ 3,4,5],关于“0.82 g/kg”的相对位置为[-5,-4,-3,- -1]。
2.2 卷积层
首先将经过BERT预训练语言模型处理的数据输入本层进行卷积,本层设计了3个卷积,每个卷积包含100个卷积核,卷积核的大小为1*3,1*5,1*7。
依据中文土壤肥力领域文本的特征,本层采用了GELU激活函数。设输入为 x ,公式为式(1)所示:
GELU( x )=0.5 x {1+tanh[2 π(x+0.044 715x3) ]}(1)
2.3 分段池化层
本层功能是将卷积层输出结果进行分段,再分别池化。由图2可知,模型将句子按照实体词的位置分段,分别为句首~实体1、实体1~实体2、实体2~句末,再分别进行池化。
句子分段完成后,对3部分分别进行填充,按照其中最长的1个分句的长度为基准,分别对另外2部分进行填充,并将填充的位置标注为 未填充的位置标注为0。
由于句子被2个实体词分为3段,每个卷积核的输出 c i同样为3份,若设卷积核的数量是n,本层的输出向量p ij是一个长度为3的向量,如式(2)所示:
p ij={p i1,p i2,p i3}
p ij= max (c ij)1≤i≤n,1≤j≤3(2)
2.4 Softmax分类层
为了防止模型过拟合,提高鲁棒性,模型在分类前经过Dropout层、ReLU层以及线性层处理池化层的输出,然后对数据进行降维操作,借助线性层将维度降到 N维,N 为关系类别。最后采用Softmax进行关系的分类,通过输入数组 z中第i个节点的值和节点的个数j ,即分类的类别数,得到Softmax函数的输出值 f ,如式(3)所示:
f i(z)=ez i jez j(3)
2.5 注意力机制
注意力机制(Attention Mechanism)是深度学习的核心技术之一,该技术参考了人类视觉系统的选择性注意机制,人类视觉可以快速扫描目标,从而获取目标中的重点区域,对其投入更多注意力资源,以获得更多关注目标的细节,而抑制其他无用信息,提高了视觉信息处理的效率与准确性[12]。借助此机制,在文本数据中可对数据进行权重分配,通过信息的重要性来确定权重,给予重要信息更高的权重分配,导致其对关系抽取产生更大的影响,从而提升关系抽取效果[13],具体过程如式(4)、(5)、(6):
e t=α(h t)(4)
α t= exp (e t)k k=1 exp (e k)(5)