项目驱动教学在网络爬虫课程中的应用研究
作者: 刘清 徐华丽
摘 要:网络爬虫课程是大数据科学与技术专业的核心课程。针对传统课堂教学的学生参与度不高、学生学习效率较低等问题,该文将项目驱动教学法应用于网络爬虫课程的教学实践。通过选择学生普遍关心的热门话题,合理设置项目难度及核心知识分布,能够不断激励、引导学生自主学习兴趣,掌握自主学习方法并最终提升学习效率。最终的测试结果表明,通过项目驱动教学,学生对数据获取、数据清洗及数据可视化等核心知识点的掌握程度有较大幅度地提升。
关键词:项目驱动;网络爬虫;python;教学研究;数据
中图分类号:G642 文献标志码:A 文章编号:2096-000X(2023)04-0043-04
Abstract: Web Crawler is the core course of big data science and technology. In order to overcome the problems of low student participation and low learning efficiency in traditional classroom teaching, a project driven teaching method is applied to the teaching practice of web crawler course in this paper. By selecting popular topics that students are generally interested in, reasonably setting the difficulty of the project and reasonably assigning the distribution of core knowledge, the awareness of autonomous learning can be enhanced for improving their learning efficiency. The final test results show that the students' mastery of core knowledge points such as data acquisition, data cleaning and data visualization has been greatly improved by the web crawler project designed in this paper.
Keywords: project-driven; Web Crawler; python; teaching research; data
大数据科学与技术是国家重点支持的新型特色专业之一,具有广阔的行业发展前景[1]。作为获取互联网数据主要技术手段的网络爬虫技术,自然受到广大师生的广泛关注[2]。
网络爬虫课程是大数据科学与技术专业的核心课程,具有区别于传统编程类课程的特点:课堂案例的爬虫代码有效期短,学生课后复习难度大。主要原因是教师在课堂上演示的爬虫程序都是针对特定网页编写的,只要目标网页的结构发生变化,演示程序就不能得到正确的结果。这一特点与C语言程序设计[3]、Java程序设计[4]等程序类课程具有明显的差异。因此,学生必须积极参与课堂教学,否则很难深入理解并掌握相关知识点。
鉴于上述特点,以教师为中心的知识点传授教学模式,必然面临诸多挑战:学生课堂参与度不高、学生课后复习难度较大及核心知识点难以深入理解等问题。
本文主要通过在网络爬虫课程中,设置难度适宜的项目,将传统知识点传授教学法与项目驱动教学法[5]有机结合起来:让学生自主设计项目解决方案,在项目实施过程中,主动发现问题并解决问题;进而全面提升学生的学习积极性、发现问题及解决问题的综合能力。
一、项目驱动教学法简介
为了进一步提升大学生的课堂学习效率并熟练掌握网络爬虫技术,本文采用项目驱动的教学方式,以学生为中心构建项目解决方案,综合提升学生的学习能力。
(一)项目驱动教学的涵义
脱离实际问题的、纯粹的知识点传授式教学,大多是枯燥与乏味的,不能引起大多数学生的学习兴趣。项目驱动教学法认为学习的动力来自解决生活中的问题;解决问题的过程便是构建知识框架、提升思维能力的学习过程。因此,项目驱动教学的核心理念就是让学生在项目实施的过程中,发现问题并自主解决问题,从而提升其学习积极性。区别于传统教学方法强调在“听中学”,项目驱动教学法则强调在“做中学”[5]。在项目驱动教学过程中,学生在项目问题的指引下,不断解决问题和发现新的问题,并最终完成整个项目任务。项目驱动教学是一种现代化的教学方法,现已广泛应用于多学科的教学实践中。
特别是在大数据时代背景下,绝大多数课程的核心知识点及常见易错问题,在互联网上都能找到原型。这就为项目驱动教学的实施提供了丰富的经验供学生学习与借鉴。
(二)项目驱动教学的特点
项目驱动教学在实施过程中,主要以小组为单位,组员之间分工明确并合作解决项目难题。项目驱动教学一般具有如下几个特点。
首先,项目的难易程度对项目实施效果有重要影响。教师要恰当选择学生感兴趣的话题,将核心知识点融入其中,并将之设计为功能较为完善、难度适中的项目。难度大的项目会挫败学生的自信心,让学生望而却步;难度过小的项目则很难引起学生的学习兴趣。难度适中的项目一般具有入手简单、多知识点相互关联等特点。这样的项目能够让学生产生解决项目的自信心,并在解决项目的过程中,不断挖掘潜在的知识点。
其次,学生是项目驱动教学的主体。在项目教学过程中,学生根据教师的指导,自主完成项目解决方案的设定、组员工作内容分工及关键核心问题的攻克等任务。学生遇到问题之后,可以选择与组员交流讨论,也可以借助网络搜索相关解决方案。教师只在必要的时候给予一定指导,以帮助学生顺利解决问题。
最后,学生的综合能力得到显著提升。在项目实施过程中,学生需要协商制定项目解决方案;需要根据学生特点,自主合理地分配项目内容;需要不断反思当前学习活动存在的问题,修正项目方案。因此,学生的合作能力、逻辑思维能力及交流与沟通能力等综合能力将得到较大的提升。
二、项目实施流程
项目驱动教学从教师设置项目开始到项目评价结束,主要包括以下几个过程。
(1)项目设计与理论教学。教师根据当前研究热点,选择具有实际应用意义的课题并将若干核心知识点融入其中,从而设计合适的项目,供学生学习。在项目实施之前,教师应当为学生开展相应的理论教学,让学生掌握一定的专业基础知识。
(2)解决方案制定与项目分工。首先,在教师的指导下,学生完成分组之后,重点协商并制定项目解决方案。在这一环节,学生需要按照软件生命周期,完成项目需求分析及解决方案的整体框架设计。其次,每个小组需要根据组员的特点及项目解决方案的结构,合理划分项目子模块,并合理分配任务。
(3)程序编码与测试。每个小组成员根据自己分配的任务,有针对性地开发相关程序,并测试程序的性能。在遇到较难的问题时,可以与组员讨论、在互联网上搜索相关案例经验或者咨询指导教师。
(4)小组答辩与教师评价。每个小组将组员的子程序模块组合为功能完善的作品,并撰写详细的说明文档。小组汇报时提供项目解决方案,项目实施过程中遇到的难题及对应解决方法。教师根据学生汇报情况,做出总结并给出若干建议,帮助学生认识自身的优势与不足,以进一步提升学生的学习兴趣。
三、项目改革实践
本文将项目驱动教学法应用于网络爬虫课程的实际教学活动中。通过问卷调查的方式,在大三学生普遍关心的小说自动下载、考研信息匹配、图书信息获取、商品比价及大学生就业分析等众话题中,选择教学项目:编写爬虫程序自动从拉勾网获取相关专业的招聘信息,并分析岗位、薪资、区域的分布情况。该python爬虫教学项目的总体要求如下。
(1)两人一组,合作完成爬虫方案选择与代码编写。
(2)使用selenium库模拟登录网页并获取相关数据。Selenium库是python爬虫常用的一种第三方工具,能够自动打开网页并模拟用户操作网页,实现元素定位、条件匹配等多种功能。
通过selenium库自动获取拉勾网招聘信息的爬虫程序主要包括三个模块:网络数据采集与存储模块、数据处理模块及数据可视化显示模块。下面简单介绍各模块的功能及实现的技术细节。
(一)网络数据采集与存储模块
登录指定URL链接地址,获取当前页的HTML文档,然后通过Css_selector选择器定位元素。定位当前页面职位信息的python语句为: Jobs=webdriver.find_elements_by_css_selector('div',[class=“job_item__1_khT”])。Jobs是一个迭代类型,包含当前页面所有职位条目,每个条目包含:职位名称、工作地点和薪资等信息。
获取到上述信息之后,可利用MySql数据库存储工作信息。数据库相关的操作函数:MySQLdb.connect函数(打开并链接数据库)、cursor()(获取游标)、cursor.execute(data)(插入数据记录)。
(二)数据处理模块
根据获取的数据,分别统计高薪工作的职业分布、区域分布及高薪岗位的共性要求。数据处理模块工作流程如下。
首先,通过python指令链接数据库,并选择数据库及指定表格。主要函数包括以下几种。
(1)conn.select_db(database_name):选择指定数据库;database_name是选择数据库的名字。
(2)cur.execute(“SELECT*FROM”+table_name):按名选择表格,table_name为选择的数据表格名称。
(3)result=cur.fetchall():获取表格数据,最终返回的result是一个元组类型变量。
其次,去除岗位信息中的多余空格,删除含有缺失信息的职位信息。String.strip()函数直接删除数据中的多余空格;在某些职位信息中可能缺失岗位的工资信息,因此需要删除该岗位信息:若job['salary']的类型为str,则删除。主要原因是:工作岗位的工资信息是一个浮点型数据,若缺失,系统会用空字符替代。
最后,将获取的招聘数据组织成列表job_list;在job_list中的每个元素是一个字典类型的数据,包含属性:发布时间、岗位名称、月工资、工作地点、链接地址、招聘单位、职位要求与说明。
(三)数据可视化显示模块
在获取到相关招聘信息之后,本文对就业信息进行分类统计和数据可视化分析。
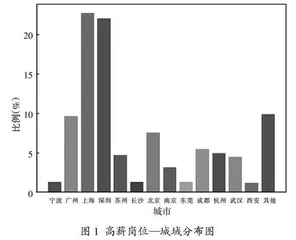
首先,统计月薪高于2万的高薪招聘岗位,并统计其区域分布。高薪岗位—城域分布如图1所示。
从图1可以看出,月薪高于2万的招聘岗位大多分布于上海、深圳、广州及北京,这四个国内的大都市,其中上海和深圳的高薪岗位占比高于21%,远高于国内其他城市。图1还说明,苏州、杭州、成都和武汉等城市的高薪岗位占比低于北京等一线城市,这与城市的整体经济水平保持一致。
其次,统计计算机方向高薪岗位的技术分类及其占比。本文重点统计了计算机方向上的传统技术及大数据技术,区块链等新兴技术的高薪岗位比例,以引导大学生根据自身兴趣,及早准备相关技术知识,为后期择业做好充足准备。各技术的高薪岗位分布图如图2所示。