数字创意产业的技术创新与商业模式创新对企业绩效的影响
作者: 李文军 李巧明
摘 要:创新是否必然带来企业绩效增长是经济管理的重要议题。现有关于创新如何影响企业绩效的研究更多使用的是专利数据、新产品销售额等数据,往往不能很好地刻画创新与创意。本文应用文本分析法中的LDA主题模型法,采用主题分析的方式构建数字创意产业的创新综合指数,用来刻画数字创意企业的技术创新与商业模式创新综合水平,并且构建了创新综合指数与企业绩效(资产收益率)之间关系的计量模型。结果表明,数字创意企业的技术与商业模式创新和创新绩效存在正相关关系,集团企业与非集团企业、所有制性质不同的企业、创新类型不同的企业以及企业规模不同的企业呈现了一定的异质性。本文为衡量创意和创新提供了新的视角,为化解创意和创新的度量困境提供了一种可资借鉴的方法。
关键词:数字创意产业;技术创新;商业模式创新;创新绩效;LDA模型
基金项目:中国社会科学院创新工程基础研究学者资助项目“技术经济学的产业视角研究”(IQTE-JC2020-2024)。
[中图分类号] F270.7 [文章编号] 1673-0186(2022)007-0067-017
[文献标识码] A [DOI编码] 10.19631/j.cnki.css.2022.007.006
在全球互联网浪潮之下,数字创意产业作为文化和科技融合的新兴领域,已成为全球经济发展的热点。《中华人民共和国国民经济和社会发展第十四个五年规划和二○三五年远景目标纲要》提出,我国要实施文化产业数字化战略,加快发展新型文化企业、文化业态、文化消费模式,壮大数字创意、网络视听、数字出版、数字娱乐、线上演播等产业。数字创意产业是战略性新兴产业的重要组成部分,是我国产业转型升级的重要方向,也与正风行于世的元宇宙概念密切相关,并为其未来创新发展奠定了基础。数字创意产业的技术创新与商业模式创新频繁发生、相互交织,深刻影响着数字创意产业的发展逻辑、发展态势与发展趋向。
一、引言
从技术创新的角度来看,影响数字创意产业的技术包括使能技术、应用技术、终端设备三个层次,这些技术也影响着数字创意产业的内容筹备、内容生产、内容分发、内容消费等各个环节。从商业模式创新的角度来看,数字创意产业广泛运用“数据+算法+内容”的商业运作模式,其中,数据是基础,算法是桥梁,内容是核心。
数字创意企业中的技术创新与商业模式创新是否会对企业绩效产生影响?产生何种影响?为了回答这一问题,首先要刻画企业的技术创新与商业模式创新。创新的表现形式丰富,特别是技术创新和商业模式创新不是某个单一指标或组合可以衡量的。就数字创意产业的创新而言,因为有很多是聚焦于情感、思想的“软创新”,它们呈现为知识产权中的商标权和著作权。著作权创作即拥有,除了音乐行业的著作权,内容生产者会去主动登记注册;其他著作权的拥有者都不会刻意去注册,很多都是等到侵权触发时,才会运用行政或者法律的途径去确定这一权利的归属。即便将商标权、著作权数据全部累加,也不足以准确反映一家数字创意企业创新的全貌。
用于刻画技术创新的研发投入和专利数据有其局限性。而对于商业模式创新的测度主要有两种常用方法,一种是指标打分法,即首先将商业模式创新的内涵进行划分和细则制定,分为几个组成部分,经过专业训练的人员依据细则,使用李克特量表等测量工具进行打分,然后再累加得出每个企业的商业模式创新指数。一些研究还会对初步打分进行质量控制。第二种方法是问卷调查法,制定针对被研究对象实际的调查问卷,然后派出调查人员开展搜集、整理等工作,最后形成企业的商业模式创新指数。这两种方法都有其科学性、可操作性,同时工作难度也较大,需要投入较大的人力物力财力,而且避免主观因素的过程控制、质量控制尤其重要。
如何准确合理衡量技术创新与商业模式创新的强度与水平是横亘在本文研究主题面前的一大难题。创新与创意两者在度量上存在困境,以往度量指标并不完美。鉴于此,本文开创性地采用文本分析的方法,充分发挥该方法的优势,使用LDA(Latent Dirichlet Allocation隐含狄利克雷分布模型,以下简称LDA模型)模型,构建了一个全新的刻画数字创意产业的技术创新与商业模式创新两者的综合型指数。通过这个指数来描述数字创意企业的技术创新与商业模式创新的活动、行为。
衡量创新绩效的基本逻辑是“投入—产出”模型。创新投入包含时间、资本、人力和信息技术,通常以R&D投入表征。创新产出则是专利、商业绩效、节约的成本、新产品的市场表现、市场收益份额、上市时间和专利转化为产品的比率等。大量的文献聚焦创新活动与企业绩效两者之间的关系。围绕创新绩效衡量,学者常采用以下三种比较主流的方法:第一,市场调研法,即通过实地调研,发放调查问卷,搜集企业技术创新和商业模式创新的实际情况,该方法更多的是和结构方程模型相结合,以发现创新对绩效的作用机制或创新的驱动因素;第二,指标核算法,即通过构建指标体系,通过打分加总的方式测算企业、国家的创新及创新绩效,在国际上衡量绩效有几个方式被广泛认可:平衡计分卡、绩效棱镜(Performance Prism)和欧洲品质管理基金会(EFQM)的质量管理等;第三,经典实证分析法,此方法中主要难点在于如何衡量创新这一指标,文献主要集中在企业、行业两大维度。
二、数字创意产业的创新综合指数构建方法
文本分析法越来越多地应用到经济学,特别是金融学领域,是大数据时代赋予的一场研究范式的革命。本文主要运用文本分析法的LDA模型,该模型由大卫(David)和乔丹(Jordan)等在2003年提出,最早发表在《机器学习研究档案》期刊上。布莱(Blei)和拉弗蒂(Lafferty)认为LDA是“最简单的主题模型”[1],并且“已被证明非常流行”[2]。
(一)文本分析法的优势
第一,避免了传统指标选取所存在的问题。在指数构建方面,文本分析法避免了创意指数的难以衡量,也避免了专利与科研投入指标的刻画不准现象,同时避免了传统商业模式创新衡量方法的高人力成本消耗。在研究对象的甄选方面,文本分析法克服了以往衡量服务业、中小型企业创新的弊端。它针对的是描述企业的财务报告、年报、新闻报道或者研究报告,通过文本计量的方式来衡量创新,将非结构化的数据提取出结构化的可用于计量分析的指标化数据。
第二,提供全新视角,避免了数据可获得性不高的问题。一是文本分析法扩大了“创新”的范围。在文本分析方法当中,它可以将关于技术创新、商业模式创新的主题提取出来,比如观察、测度文本中关于“研发”“价值”“用户”“成本”“收入”等主题的论述,拓宽了创新测度的范围。二是在选择符合本文研究范畴的企业样本中,只有寥寥几家企业有新增专利数的数据,其他专利数据都是缺失的,如果仅仅基于专利的话,本文的样本数量严重不足。文本分析的方法则可以突破该局限,能尽可能多地搜集更多的企业,而且时间的跨度也更长,还能规避专利数据的跨期申请、为满足保密需求滞后申请、为迷惑竞争对手伪申请等问题。
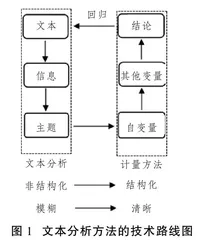
第三,节约了研究的人力成本,可以提炼结构化变量。文本分析的方法通常一下子处理几万份文档,若是要人工去一篇篇阅读如此大规模的文档,并且萃取最具代表性的主题信息是一大挑战。该方法依据算法和机器学习,自动提供整个语料库的主题,节约大量的人力成本,数据处理规模也大,同时还避免了人工处理过程当中可能出现的误读、被“茫茫信息淹没”的现象。大数据实时流动,来源广泛,海量且分散,呈现分布碎片化、主题模糊化、文本非结构化等特征。通过文本分析的方法,可以从碎片化的数据中提炼结构化的变量,从而获得高价值密度的信息,将模糊的主题变得清晰,同时还将非结构化的文本结构化,实现从文本到结论的转化,形成整体性的认知图景。而形成的结论反过来又可以回归文本,从文本中找出相应的片段式或整体性的经验与描述去进一步论证结论(图1)。
(二)LDA方法的具体内涵
LDA是一种主题模型,属于信息提取方法中的无监督学习方法之一,是自然语言处理(NLP)中应用较为广泛的基础性模型。LDA模型是三层贝叶斯概率模型,基于离散数据集合(如文本语料库),每个集合都是由一系列主题构成,且主题以概率分布的方式呈现。换而言之,它将一篇文档看作词汇的集合,而词汇则是围绕文档的主题生成。所以主题模型主要是构建文档—词—主题之间的关系,核心逻辑在于把文档进行分词,然后根据词与词之间的共现与邻近(也可以加上语义关系)等,进行聚类(也就是获得主题),最后形成文档—词频分布矩阵,词—主题分布矩阵,以及文档—主题分布矩阵。
根据在具体的操作中,LDA假设一个语料库D中的每个文档d的生成过程如下:
1.选择 N ~ Poisson(ξ)。即词汇服从泊松分布。
2.选择θ ~ Dir(α)。θ服从参数为α的狄利克雷分布,θ是一个多项式分布。θd表示文档d中所包含的每个主题的比例,它是文档d的主题分布,是个向量。
3.对于N中的每个词wn:
(1)根据θd进行主题指派,得到文档d中词n的话题zd,n即从文档中的主题分布采样词n的主题zn;(2)根据指派主题所对应的词分布中采样出词wn(每个主题有各自的词汇分布,词汇分布同样是多项分布,服从Dirichlet分布,参数为β)。
重复上述过程,遍历M篇文档。
给定参数α和β,主题混合分布θ、主题z和文档d的联合分布,如式(1)所示:
简而言之,在LDA模型中一共有三个分布:(1)每篇文章中的主题分布,即θd,其中d∈D;(2)每个主题中的词汇分布,即zn;(3)每篇文章中的词汇分布,即wn。有两个参数:假定给定了狄利克雷分布的参数α和β。
从通俗意义上来理解,图2是在用一个模型来模拟作者撰写文章的过程(即“文档生成过程”)。虽然每个人写文章的方法不一样,但是大致有个规律。而这个图就是David M. Blei等绘制的,他们将作者撰写文章的过程分为两步:第1步,作者先从所有的主题里选择几个主题,也就是图里θ→z的过程,其中θ依赖于参数α;第2步,作者将每个主题,写成句子(即前文所述的指派主题),按照统计学方法来说,其实也就是在这个主题之下选择对应的词汇组合起来,因此也是一个随机选择过程,即图中z→w的过程。换言之,就是“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”。
David M. Blei等认为θ→z和z→w这两个随机过程都可以用狄利克雷分布来描述,因此可以通过训练来估计这两个随机过程对应的模型参数。训练完成后,可以用这个模型去反推(图3),对于一篇新的文章,根据它的结果(也就是w),去推测这篇文章的各个主题的概率(也就是θ→z)。而反推的原理则是基于贝叶斯原理,所以LDA一般被认为是PLSA(Probabilistic latent semantic analysis,概率潜在语义分析)的贝叶斯化版本。
三、数字创意产业的创新综合指数构建
本文使用LDA模型分析文本,从而构建新的变量来刻画技术创新与商业模式创新的程度。在具体的数据操作过程中,核心点在于构建描述技术创新与商业模式创新的主题词表,通过LDA模型生成的主题词进行比对,形成最终的创新度量指数。具体的数据操作过程可以分为三步:数据采集、数据处理和主题分析,技术路线如图4所示:
(一)样本确定
本文根据实证研究需要从万得(Wind)金融数据库、新浪财经中关于2014—2019年数字创意企业的年报、研究报告和财务数据中获取数据源。万得金融数据库的研究报告数据不及新浪财经丰富,且时间跨度较短,所以两者相结合,形成一个更加全面的数据源。进一步使用Python,从数据源中爬取文本,形成两个维度的数据予以分析:一是“他者”的视角,即分析师的研究报告;二是“本我”的视角,即上市公司本身的每年年报。长期以来分析师撰写的研究报告具有显性信息含量,且与分析师在行业内的评级、声誉挂钩。因而很多研究将分析师的研报作为一个重要的指标来源。年报亦是如此,披露年报是上市公司的法定职责,且受到外部审计的监督。由此形成的“他者”和“本我”两方观点,构建了多维视角以期更完整更全面地反映上市公司在技术创新和商业模式创新活动以及两者所带来绩效的真实情况。