基于机器学习算法的超大城市运行管理现代化水平监测模型研究
作者: 刘莉 周文煊超大城市作为全球化进程中的核心节点,具有资源、人口和基础设施高度集中的特点,是社会经济发展的重要引擎。数据科学和人工智能技术的快速发展为超大城市运行管理的量化研究提供了新的可能性,目前的数据驱动方法多聚焦于具体应用场景,尚未形成覆盖超大城市运行管理现代化水平的综合监测模型。结合机器学习中的非监督学习聚类算法、统计分析方法以及大数据挖掘技术,本研究构建了超大城市运行管理现代化水平监测的算法模型,旨在反映超大城市在管理体系和运行效率方面的现状与挑战。基于研究结果,选择了国内典型超大城市北京、上海、广州、深圳进行实例应用与验证。结果表明,所设计的算法模型能够有效揭示城市运行管理中的潜在问题与发展瓶颈。研究成果旨在为超大城市运行管理水平的评估和提升提供科学的算法模型支持,为相关政策制定与管理实践提供理论依据和应用参考。
一、超大城市运行管理现代化水平监测指标体系
在技术路线上,本研究首先构建超大城市运行管理现代化水平的监测指标体系,确定各指标权重;其次运用DBSCAN(Density-Based Spatial Clustering of Applications with Noise,基于密度的噪声应用空间聚类)聚类算法识别数据空间中的高密度区域和异常数据点,以提高监测结果的可靠性;进而结合三西格玛(3g)原则与等比缩放算法,测算指标数据阈值区间及目标值,并构建现代化水平识别模型;最后通过等宽离散化方法划分管理水平等级,验证模型的科学性与可行性。
(一)体征指标
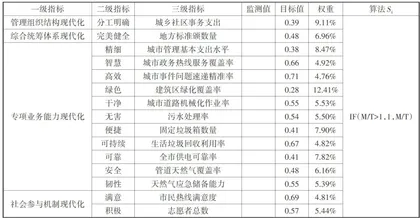
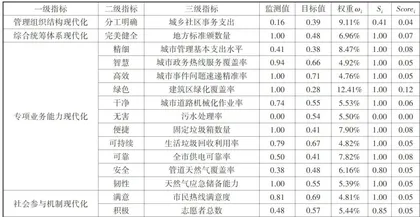
参考学者陆军和杨浩天的研究方法,以管理组织结构现代化、综合统筹体系现代化、专项业务能力现代化和社会参与机制现代化四个核心维度,选取15项超大城市运行管理现代化监测指标数据,反映超大城市运行管理现代化水平[1(如表1所示)。
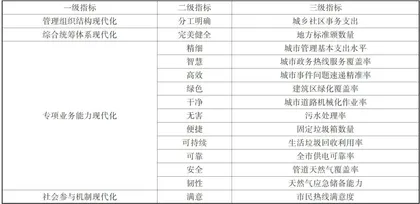
(二)特征权重
采用变异系数法[2确定权重。该方法依据数据的变异程度赋予不同权重,变异程度越大,指标在综合评价中的重要性越高。由于模型数据涵盖不同领域和监测对象,变异系数能够有效衡量数据的离散程度,从而增强可比性。其计算过程如下:
1.数据归一化处理:
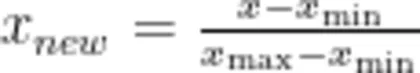
2.计算均值与标准差:
(1)均值的计算公式为:
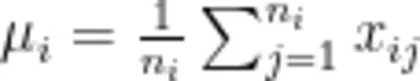
(2)标准差的计算公式为:
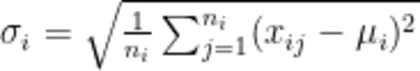
3.计算变异系数:
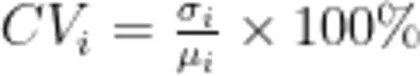
4.计算模型权重:
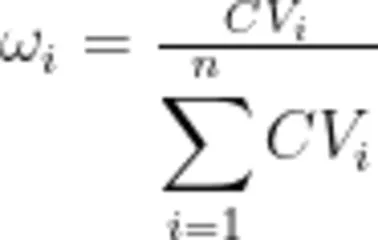
注:  表示第i个数据的权重,n为数据维度。
表示第i个数据的权重,n为数据维度。
二、超大城市运行管理现代化水平监测模型建构
本文采取多目标决策分析法[3],综合考量超大城市运行管理现代化的各个关键因素从而探寻超大城市运行管理现代化水平状态。超大城市运行管理现代化水平指标数据为无量纲的百分比数据。其中的数据主要来源于中国城市统计年鉴委员会2022年发布的《中国城市统计年鉴》,如地方财政城乡社区支出,城市管理支出等;权威媒体的新闻报道,如北京市的全市供电可靠率、天然气管网覆盖率等;各地政府统计网站,如全市机械化作业率,城市政务通自动覆盖率等。
首先,采用非监督学习聚类算法对原始数据进行预处理,通过消除数据噪声、剔除异常值并处理缺失数据提升数据质量和分析的准确性。在此过程中,聚类算法能够自动识别数据中的自然分组,无须预先设定类别,使数据结构更加清晰。此外,聚类算法在异常值检测方面具有显著优势,可为城市运行管理现代化水平的监测预警提供有力支持。与此同时,该方法能够实现高效、高精度的数据清洗,使后续分析基于更加精准和可靠的数据展开。4]其次,基于清洗后的有效数据使用统计学习算法建立各个指标的阈值区间。最后,根据实际数据与阈值的偏差百分比分析各个指标表现得分。该方法具备较强的适应性和可扩展性,可结合不同城市或不同时期的数据进行调整,使评估结果更加科学、客观,为城市风险管理提供有力的数据支撑。[5]
(一)阈值区间
本文选取北京、上海、广州、深圳4座典型超大城市2022年的城市运行管理现代化数据,采用基于机器学习的聚类算法建立指标数据的目标值。
首先用DBSCAN算法检测噪声数据和离群值并进行剔除。DBSCAN是一种基于密度的聚类算法,广泛应用于噪声数据和离群值检测。该算法通过设定邻域半径 ( ε ) 和最小样本数 ( M i n P t s ) ,在数据空间中识别高密度区域,并将低密度区域的数据点视为噪声或离群值。与传统的K-Means等方法不同,DBSCAN无须预设簇的数量,能够自动识别数据中的自然结构,尤其DBSCAN能够识别任意形状的簇,而不仅限于球状或均匀分布的数据,提高了聚类的适用性。6]
本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:cqxz20250213.pd原版全文
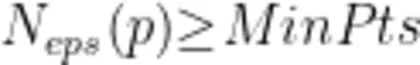
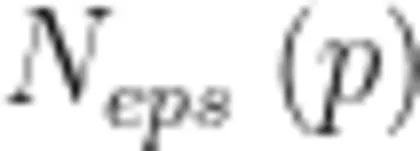 表示在以点 p 为中心, e p s 为半径的邻域内的数据点数量,如果这个数量不小于最小点数 M i n P t s ,则点 p 就是一个核心点。
表示在以点 p 为中心, e p s 为半径的邻域内的数据点数量,如果这个数量不小于最小点数 M i n P t s ,则点 p 就是一个核心点。
然后使用三西格玛 3 σ 原则确定阀值区间。三西格玛 3 σ 原则假设数据服从正态分布,并以均值 ( μ ) 和标准差 ( σ ) 为基础设定阈值区间,即 μ ± 3 σ 。在正态分布下,超出此范围的值通常被视为异常,从而进行风险检测和异常识别。
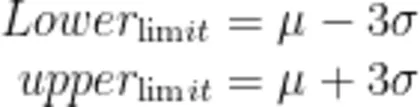
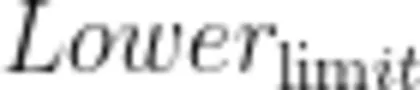 与
与 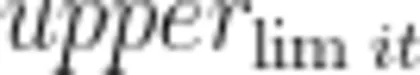 分别为阈值区间的下限和上限,如果数据点落在这个范围之外则判定为离群值进行剔除。
分别为阈值区间的下限和上限,如果数据点落在这个范围之外则判定为离群值进行剔除。
最后,对剩余的数据计算均值作为目标值。
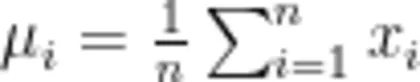
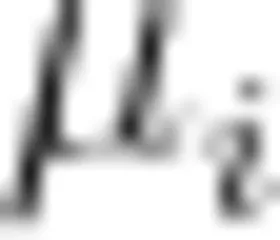 表示均值
表示均值 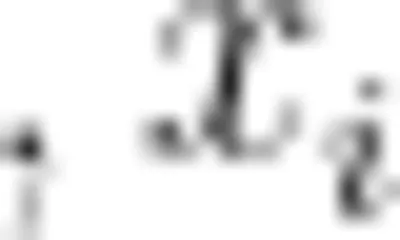 表示第 i 个数据点的值, n 表示数据点的数量,经过上述步骤,原始数据得到清洗,形成干净数据集后确定了对应的目标值 。
表示第 i 个数据点的值, n 表示数据点的数量,经过上述步骤,原始数据得到清洗,形成干净数据集后确定了对应的目标值 。
(二)模型建构
基于等比缩放算法构建城市运行管理现代化水平识别模型,以目标值作为决策分数的判定依据。目标值作为数据的理想状态,是分析和决策的重要参考。当监测值不低于目标值时,表示该指标表现良好;低于目标值则反映出监测数据较差。评分计算方式为监测值与目标值的比值乘以理论最大分数。对于目标值为100 % 的情况,由于观测值不会超出目标值,其决策分数同样按照该比值与最大分数计算。
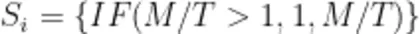
其中, 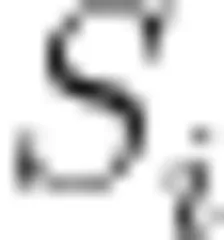 代表第i个指标的客观得分,T代表目标值, M 代表实际监测值。基于以上方法建立城市运行管理水平监测模型(如表2所示)。
代表第i个指标的客观得分,T代表目标值, M 代表实际监测值。基于以上方法建立城市运行管理水平监测模型(如表2所示)。
(三)超大城市运行管理现代化水平评分与等级划分
计算超大城市运行管理现代化水平得分公式为:
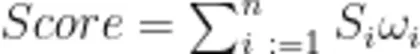
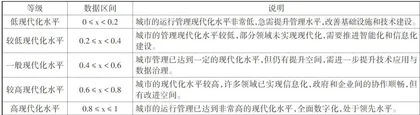
基于超大城市运行管理现代化水平模型权重和决策算法,使用等宽离散化方法将超大城市运行管理现代化水平划分为五个等级,详细分级情况如表3所示。
三、超大城市运行管理现代化水平监测模型检验
为了验证算法模型的有效性和可行性,以北京、上海、广州、深圳作为实例分析对象。通过收集相关指标数据,结合等比缩放算法对城市运行管理进行建模分析,并进一步评估算法在实际应用中的表现。其中北京市运行管理现代化水平结果如表4所示,其他城市因篇幅原因不在正文中展示;四座超大城市运行管理现代化水平总评结果及其一级指标项得分结果如表5所示。

本文为全文原貌 未安装PDF浏览器用户请先下载安装
原版页码:cqxz20250213.pd原版全文