基于大数据的智能农业云服务平台设计与实现
作者: 江顺 陈荣宇 林伟君 吴丽丹
摘要 以Lambda Architecture大数据技术框架为基础,应用HDFS、Hadoop MapReduce、Storm等一系列大数据处理和分析技术,并基于云计算服务,构建了一种基于大数据的智能农业云服务平台。该平台设计为3层大数据云服务架构,从底层至系统上层依次为云服务层、大数据系统层和应用层。平台支持农业资源基础数据、农业生产数据、生产经营主体数据、市场信息数据、科技服务数据的查询浏览、统计分析、信息共享、信息发布等功能,解决了现代农业产业园背景下,农业经营的全产业链大数据管理和分析的应用问题,系统在广东省部分现代农业产业园初步部署。
关键词 农业大数据;云服务 HDFS;农业信息系统
中图分类号 S-058 文献标识码 A
文章编号 0517-6611(2022)16-0190-08
doi:10.3969/j.issn.0517-6611.2022.16.047
开放科学(资源服务)标识码(OSID):
Design and Implementation of Intelligent Agricultural Cloud Service Platform Based on Big Data Technology
JIANG Shun1,2,CHEN Rong-yu3, LIN Wei-jun1,2 et al
(1.Institute of Agricultural Economy and Information, GAAS, Guangzhou, Guangdong 510640;2.Key Laboratory of Urban Agriculture in South China, Ministry of Agriculture and Rural Affairs,Guangzhou,Guangdong 516040;3.Haifeng Agricultural Science Research Institute, Haifeng, Guangdong 516400)
Abstract Based on the big data technology framework of Lambda Architecture,we applied a series of big data processing and analysis technologies, such as HDFS, Hadoop MapReduce and Storm.Based on cloud computing services, we constructed an intelligent agricultural cloud service platform based on big data.The platform was a three-tier big data cloud service architecture, from the bottom layer to the top layer of the system were cloud service layer, big data system layer and application layer.The platform supported the query and browsing, statistical analysis, information sharing, information release and other functions of agricultural resource basic data, agricultural production data, production and operation principal part data, market information data, science and technology service data.It also solved the modern agriculture under the background of industrial park, the application of big data management and analysis in the whole industrial chain of agricultural management was preliminarily deployed in some modern agricultural industrial parks in Guangdong Province.
Key words Agricultural big data;Cloud services HDFS;Agricultural information system
进入21世纪,大数据、物联网和云计算技术推动信息技术和互联网进一步蓬勃发展,现阶段互联网成为了正在发展中的高效率信息库和信息交换中心,使人类生产生活方式产生了巨大变革,大数据技术和云计算技术是这一阶段信息技术和互联网发展的核心焦点[1-5]。物联网技术的更新迭代促使万物互联的互联网时代来临,网络数据规模进一步膨胀,这些数据中大部分为非结构化数据。据IDC的调查报告显示,企业中80%的数据是非结构化数据且这些数据每年都按指数增长60%(该年度数据规模为前1年的1.6倍)。大数据系统既是在这样一个时代背景之下诞生,使这些非结构化数据被有效管理和利用成为可能[1]。从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分,大数据必然无法用单台的计算机进行处理,必须采用分布式架构,它的特色在于对海量数据进行分布式数据挖掘,但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术[6]。
随着物联网、大数据、云计算等技术应用领域不断下沉至社会生活生产实践中,数字农业也越来越成为现在和未来农业产业发展的焦点,数字农业在中国农业生产中应用的不断加深,促使中国传统农业的生产方式发生重大变革,越来越多粗放的、机械的、经验的生产模式不断向集约化、智能化、科学化发展[7-9]。如今数字应用已经成为工业生产和社会生活的主流,而农业生产中数字化技术应用仍然处于初创期,农业领域可能是信息化和数字化普及的最后一个产业[8]。导致农业领域数字化技术的应用普及缓慢的原因是多层次的,其中最主要的原因在于中国农村分散的生产经营模式不利于信息化系统的数据资源集中。而随着农村通信基础设施的不断完善、农业物联网技术的逐步成熟,国家大力推动现代农业产业园的建设,农业全产业链的数据集成成为可能[8-9]。鉴于此,笔者在对大数据架构的研究基础上提出一种基于Lambda Architecture大数据架构的农业云服务平台解决方案。
1 研究方法与关键技术
1.1 Lambda Architecture大数据架构
Lambda 架构(Lambda Architecture)是由工程师南森·马茨(Nathan Marz)根据他在Backtype和Twitter从事分部式数据处理系统工作的经验提出的大数据处理架构,其目的是指导用户充分利用批处理和流式技术各自优点,用于实现复杂的大数据系统[10]。在大数据处理系统中,批处理系统(如Hadoop MapReduce)具有较高的可靠性,但数据的实时性较差;流式处理系统(如Storm)则情况正好相反,数据处理延迟低,但可靠性差强人意。Lambda Architecture的目的即为协调2种技术的优缺点,使得大数据处理系统既满足高可靠性需求,又具有较低的延迟性。Lambda Architecture设计主要目的是满足以下4个方面的需求:①系统故障或人为错误不丢数据;②数据分析低延迟;③系统具备线性扩展能力;④系统中很容易增加新特性。
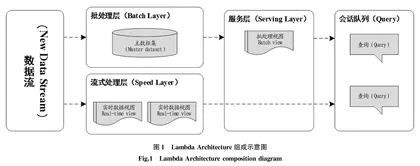
Lambda Architecture由批处理层(batch layer)、流式处理层(speed layer)、服务层(serving layer)组成(图1)。
(1)批处理层[11-12]。批处理层的主要职责是保证数据处理的准确性和可靠性,该层将数据以原始格式存储于HDFS上,以保障和加强数据系统的可靠性,利用Hadoop MapReduce框架对数据进行处理,并保存计算结果,经该处理过程后的数据视图称之为批处理视图(Batch View)。Hadoop MapReduce框架具有优秀的鲁棒性,运行过程中即使出现异常也不会产生数据丢失。这种批处理方式只需要数据存储系统进行随机读取、追加写入操作,不需要处理随机写、加锁、数据一致性等问题,因而较大简化了存储系统的设计。但是批处理层的数据处理通常有几小时到几天的延迟。
(2)流式处理层[13]。流式处理层的主要职责是满足所有实时性处理的需求。流式处理层通常基于Storm这样的流式计算平台,通过快速的增量式算法,以分钟级、秒级甚至毫秒级来读取、分析、保存数据。对于存储系统,由于需要支持持续的更新操作,其设计要复杂得多。为了简化问题,通常使用划窗机制来保存一段时间的数据,划窗的时间一般和批处理层的数据处理一致。流式处理往往使用内存计算,这意味着当出现异常(比如升级或工作节点异常)时,可能会导致数据的丢失或计算结果错误。然而,Lambda Architecture却不需要过多考虑这类问题,因为下一次批处理作业会再次处理所有数据并获得准确的结果。
(3)服务层。流式处理层的服务层职责是将流式处理层输出数据合并至批处理输出数据上,从而得到一份完整的输出数据,并保存到诸如HBASE这样的NoSQL数据库中,以服务于在线检索应用。在批处理计算结果之上结合少量实时数据,其结果与完全使用批处理计算相比,具有很好的近似性。
1.2 分布式文件系统
分布式文件系统[14-16](Distributed File System,DFS)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单理解为一台计算机)相连。Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是指被设计成适合运行在通用硬件(Commodity Hardware)上的分布式文件系统[14]。HDFS有高容错性(Fault Tolerant)的特点,并且设计用来部署在低廉的(Low Cost)硬件上。而且它提供高吞吐量(High Throughput)来访问应用程序的数据,适合那些有超大数据集(Large Data Set)的应用程序。HDFS放宽了POSIX的要求,这样可以实现流的形式访问(Streaming Access)文件系统中的数据。
1.2.1 HDFS的结构。HDFS由4部分组成(图2):HDFS客户端(HDFS Client)、名称节点(Name Node)、数据节点(Data Node)和辅助名称节点(Secondary Name Node)。HDFS是1个主-从(Mater/Slave)体系结构,HDFS集群拥有1个名称节点和一些数据节点。名称节点管理文件系统的元数据,数据节点存储实际的数据[15]。
(1)名称节点:负责管理分布式文件系统的命名空间(Namespace),保存了2个核心的数据结构,即镜像文件(FsImage)和操作日志(EditLog)。镜像文件用于维护文件系统树以及文件树中所有的文件和文件夹的元数据。操作日志文件中记录了所有针对文件的创建、删除、重命名等操作。
(2)HDFS客户端:提供一系列命令用于管理和访问HDFS,如启动和关闭HDFS。用于与数据节点交互,读取或者写入数据;读取时,要与名称节点交互,获取文件的位置信息;写入HDFS时,Client将文件切分成多个的数据块(Block),然后进行存储。